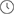 發布時間:2023-07-20
發布時間:2023-07-20

CXL(Compute Express Link),是一種全新的設備互聯技術標準,已成為業界突破內存瓶頸的存儲新技術。不僅用于內存容量/帶寬擴展,還用于異構互聯,數據中心資源池解耦。在數據中心,CXL技術可以將不同的計算和存儲資源進行互聯,用更高的系統性能和效率來解決數據中心內存問題。
云計算、大數據分析、人工智能、機器學習等應用的快速發展帶來數據中心存儲和處理數據需求的爆炸性增長。傳統DDR內存接口存在總帶寬、每核心平均帶寬和容量可擴展性受限等問題。尤其在數據中心,受限于大量內存問題,新的內存接口技術CXL出現。
在數據中心,CPU內存是緊耦合關系,每代CPU都采用新的內存技術實現更高的容量和帶寬。自2012年以來,核心數量迅速增長,但每個內核的內存帶寬和容量并未相應增加,反而下降。這種趨勢將在未來繼續,內存容量增長速度也快于內存帶寬,這對系統性能影響巨大。
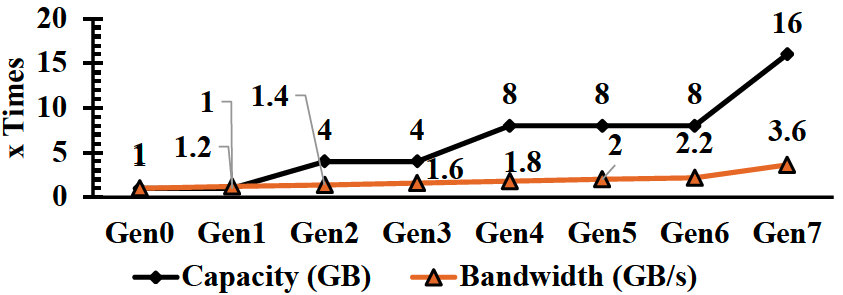
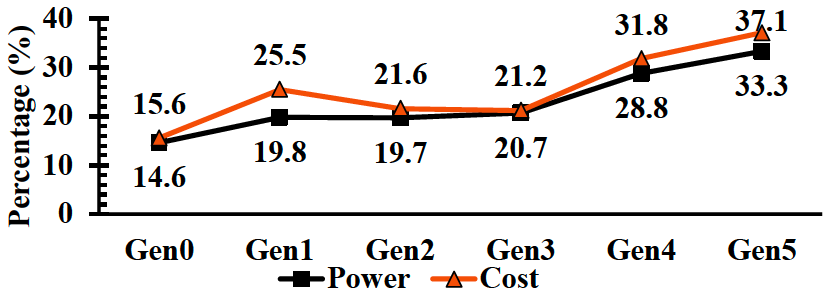
此外,直連DRAM和SSD在延遲和成本方面的巨大差距,使得昂貴的內存資源往往利用率很低,錯誤的計算和內存比例很容易造成內存閑置(Stranded)租不出去的現象。數據中心業務作為全球資本最密集的行業之一,低利用率是一個很大的負擔。微軟表示,50%的服務器總成本來自DRAM。盡管DRAM成本很高,但25%的DRAM內存還是浪費了。下圖來自Meta內部的統計數據也顯示類似現象。內存成本占系統總成本的比例實際上在不斷上升,系統的主要成本已經變成是內存而不是CPU本身,使用CXL內存資源池可以有效改善這一問題,通過給系統動態分配內存資源可以優化計算和內存比例關系優化TCO。

不同內存技術的延遲概況
內存帶寬/容量隨時間推移增加
不同代內存在機架TCO/功耗占比
Microsoft Azure內存閑置
基于傳統內存問題,業界一直在尋求采用新的內存接口技術和系統架構。
在內存接口技術方面,PCI-Express(peripheral component interconnect express)成為首選。PCIe是串行總線,使用PCIe從性能和軟件的角度來看不同設備之間通信的開銷相對較高,但好消息是,PCIe將按照計劃在2023年底完成7.0版的批準,提供高達256GB/s 的速率;這距離16 GT/s速率的4.0版PCIe問世還不到兩年。加速PCIe發展藍圖的主要推手是云端運算需求;而PCIe以往是每3~4年,甚至是7年會將數據傳輸速率提升一倍。
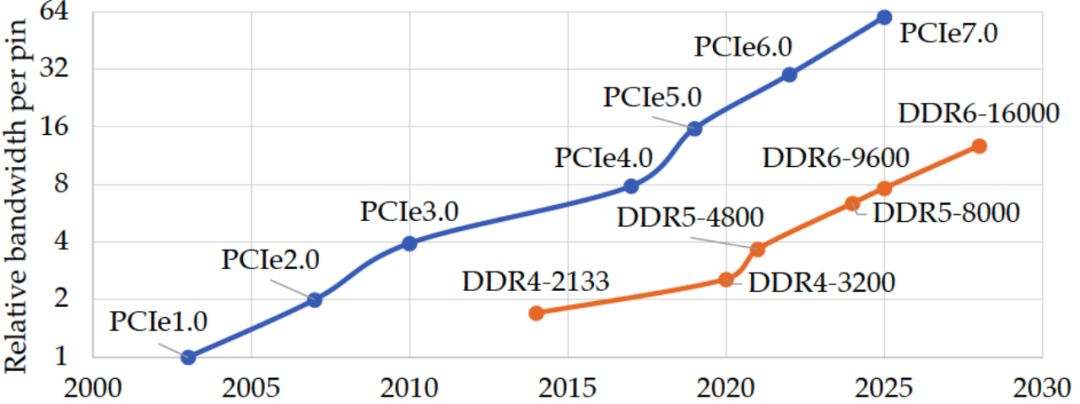
PCIe vs DDR 帶寬對比
系統架構則是歷經幾代進化更迭。最初為實現多個服務器共享資源池的嘗試,通常使用RDMA技術在通用以太網或InfiniBand上面實現,這些通信方法通常時延更高(本地內存幾十納秒vsRDMA幾個微秒)和更低的帶寬,而且也無法提供內存一致性等關鍵功能。

在40Gbps鏈路帶寬網絡可實現的往返延遲(總計)
以及導致往返延遲增加的組件(使用100Gbps可將數據傳送減少0.5us)
2010年,CCIX成為潛在的行業標準。它的驅動因素是需要比當前可用技術更快的互連,并且需要緩存一致性,以便在異構多處理器系統中更快地訪問內存。CCIX規范的最大優勢是它建立在PCI Express規范的基礎之上,但它因缺乏關鍵行業支持,從未真正起飛。
而CXL依托現有的PCIe5.0的物理層和電氣層標準及生態系統,為內存加載/存儲(load/Store)事務增加緩存一致性和低時延特性。由于建立了行業中大多數主要參與者都支持的行業標準協議,CXL使向異構計算的過渡成為可能并獲得廣泛的業界支持。AMD的Genoa和Intel的SapphireRapids將在2022年末/2023年初支持CXL1.1。至此,CXL成為業界和學術界最有前途解決這一問題的技術之一。
CXL構建在PCIe物理層上,具備現有PCIe物理及電氣接口特性,提供高帶寬,高可擴展性特點。另外CXL與傳統的PCIExpress(PCIe)互連相比具有更低的時延,而且還提供一組獨特的新功能使CPU能夠以具有加載/存儲(load/store)語義的高速緩存一致(Cache-Coherent)方式與外圍設備(內存擴展和加速器及其連接的存儲器)通信。該技術保持CPU內存空間和附加設備上內存的一致性,允許資源共享,從而獲得更高性能,降低軟件棧復雜性。與內存相關的設備擴展是CXL主要目標場景之一。

CXL依托現有PCIe物理及電氣接口特性
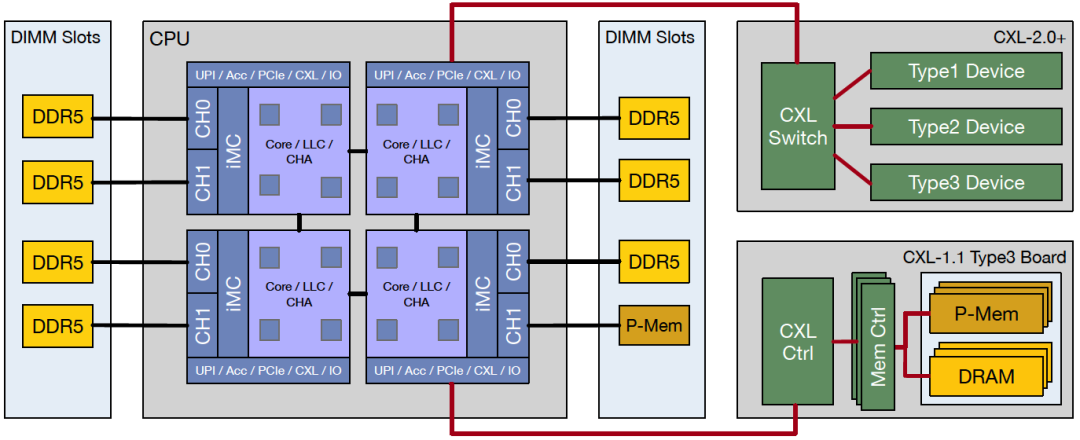
CXL/PCIe實現內存資源擴展/池
CXL實際上包含三種協議,但并非所有協議都是延遲的靈丹妙藥。CXL.io(運行在PCIe總線的物理層上)仍然具有與以往相同類型的延遲,但其他兩個協議,CXL.cache和CXL.mem采用了更快的路徑,減少了延遲。大多數CXL內存控制器會增大約100-200納秒的延遲,額外的重定時器會增加或花費幾十納秒,具體取決于設備與CPU的距離。
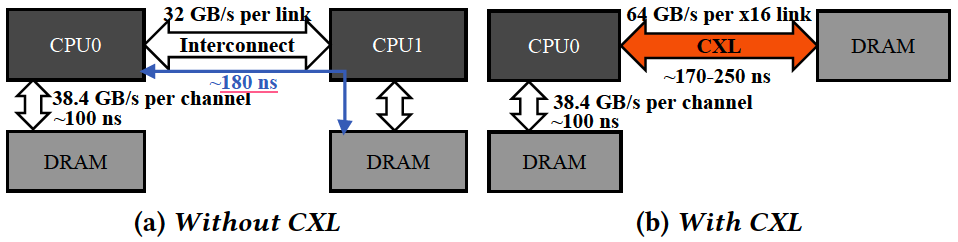
CXL引入時延與NUMA接近
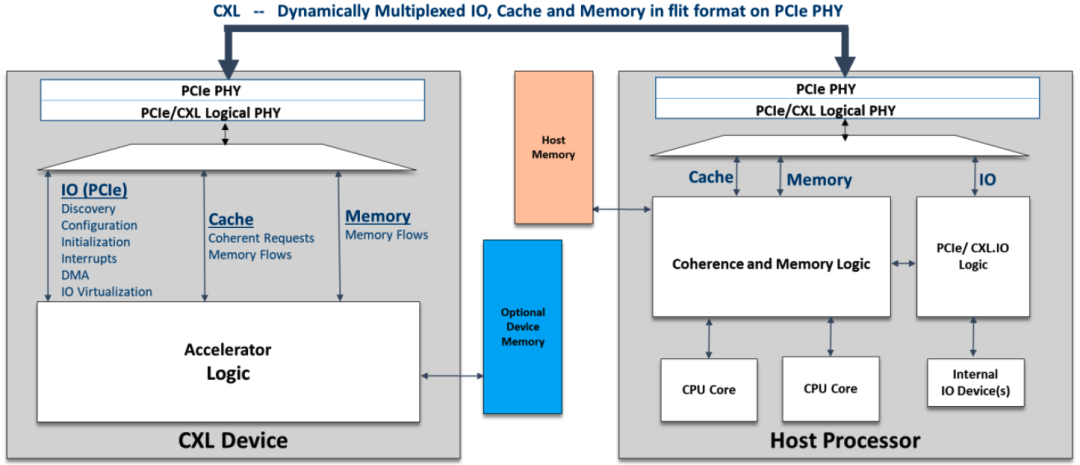
CXL/PCIe擴展內存系統架構
CXL在PCIePHY層復用不同的協議,CXL1.0/1.1規范附帶3個協議支持-CXL.io、CXL.cache和CXL.mem,大多數CXL設備將使用CXL.io、CXL.cache和CXL.mem的組合。CXL.io 使用與 PCIe 相同的事務層數據包 (Transaction Layer Packet, TLP)和數據鏈路層數據包 (DLLP)。TLP/DLLP覆蓋在CXL flit的有效負載部分上。CXL定義了跨不同協議棧提供所需服務質量(QoS)的策略。PHY級別的協議復用可確保CXL.cache和CXL.memory等延遲敏感協議具有與本機CPU到CPU對稱一致性鏈路相同的低延遲。CXL為這些延遲敏感協議定義了引腳到引腳響應時間的上限,以確保平臺性能不會因實現一致性和內存語義的不同設備之間的延遲差異較大而受到不利影響。
由于安全使用其本地副本,CXL.cache允許CXL設備連貫地訪問和緩存主機CPU的內存,可以把這想象成一個GPU直接從CPU的內存中緩存數據。
允許主機CPU連貫地訪問設備的內存,將此視為CPU使用專用存儲級內存設備或使用GPU/加速器設備上的內存。

從左向右依次是CXLType1、CXLType3、CXLType2
CXL 2.0增加了對內存池和CXL交換的支持,允許眾多主機和設備全部鏈接并相互通信,從而使連接在CXL網絡上的設備數量顯著增長。多臺主機可以連接到交換機,然后將交換機連接到各種設備,如果該CXL設備是多頭的并連接到多個主機的根端口,則也可以在沒有交換機的情況下實現。SLD(單個邏輯設備)是單個主機分別使用不同內存池,MLD(多個邏輯設備)旨在耦合多個主機以分享同一物理內存池。
分布式內存資源網絡將由結構管理器(FabricManager)負責分配內存及設備編排,它相當于控制平面或協調器,位于單獨的芯片上或交換機中,通常不需要高性能,因為不接觸數據面。結構管理器(FabricManager)提供用于控制和管理該系統的標準API,可以實現細粒度的資源分配、熱插拔和動態擴容允許硬件在各個主機之間動態分配和轉移,無需任何重啟。將所有這些結合在一起,微軟報告顯示采用CXL方式實現內存資源池整體可減少10%內存需求,進而降低5%的總服務器成本的潛力。


CXL 2.0內存資源池(Switch vs Directconnect模式)
CXL發展勢頭強勁,三星、SK海力士、Marvell、Rambus、三星、AMD等大廠們的布局也在不斷加速。公有云供應商在內的所有超大規模企業都開始嘗試依賴CXL連接內存池來改善內存閑置,動態靈活增加帶寬和容量的問題。但當前沒有太多用于APP使用本地/外部混合資源池的多級內存調度管理監控技術,因此云服務商如果決心大規模使用基于CXL技術的資源池系統,要么自己建,要么得尋找合適的系統軟硬件供應商。這方面微軟、Meta等主要云服務商已經走到前面。
微軟的Pond方案使用機器學習判斷分析虛機是否是時延敏感以及不被使用的額(untouched)內存大小,并由此來判斷調度VM在合適的本地或CXL遠端內存位置,配合性能監控系統不斷調整遷移。
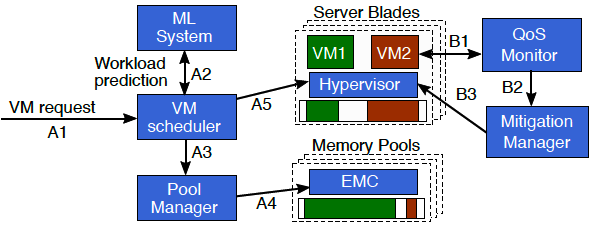
微軟Pond方案控制平面工作流程
(A) 的VM 調度程序使用基于 ML 的預測來識別延遲敏感的虛擬機及其可能未觸及的內存量決定虛擬機的放置
(B) 監控如果服務質量 (QoS) 不滿足,調度遷移控制管理器(Mitigation Manager)會重新配置虛擬機
作為智算中心網絡建設者,銳捷網絡致力于為客戶提供創新的產品方案和服務,推動行業發展和創新,讓客戶與未來更緊密地連接。銳捷網絡將持續創新,引領智算時代的網絡發展潮流。
TPP: Transparent Page Placement for CXL-Enabled Tiered-Memory
Pond: CXL-Based Memory Pooling Systems for Cloud Platforms
Demystifying CXL Memory with Genuine CXL-Ready Systems and Devices
Compute Express Link™ Specification 3.0 whitepaper
Design and Analysis of CXL Performance Models for Tightly-Coupled Heterogeneous Computing
Memory Disaggregation: Advances and Open Challenges
Network Requirements for Resource Disaggregation
A Case for CXL-Centric Server Processors

 文檔評價
文檔評價



















