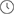 發(fā)布時(shí)間:2023-03-20
發(fā)布時(shí)間:2023-03-20

AIGC(AI-Generated Content,人工智能生產(chǎn)內(nèi)容)近期發(fā)展迅猛,迭代速度更是呈現(xiàn)指數(shù)級(jí)的爆發(fā)式增長(zhǎng)。其中,GPT-4和文心一言的推出引起了人們對(duì)其商業(yè)價(jià)值和應(yīng)用場(chǎng)景的高度關(guān)注。隨著AIGC的發(fā)展,訓(xùn)練模型參數(shù)規(guī)模從千億到萬(wàn)億級(jí)別,底層GPU支撐規(guī)模也達(dá)到了萬(wàn)卡級(jí)別。由此導(dǎo)致的網(wǎng)絡(luò)規(guī)模不斷增大,網(wǎng)絡(luò)節(jié)點(diǎn)間通信面臨著越來(lái)越大的挑戰(zhàn)。在此背景下,如何提升AI服務(wù)器計(jì)算能力和組網(wǎng)通信能力并兼顧成本,已成為當(dāng)前人工智能領(lǐng)域的重要研究方向之一。
銳捷網(wǎng)絡(luò)針對(duì)AIGC算力、GPU利用率與網(wǎng)絡(luò)的關(guān)系,以及主流HPC組網(wǎng)面臨的挑戰(zhàn),推出了業(yè)界先進(jìn)的“智速”DDC(Distributed Disaggregated Chassis,分布式分散式機(jī)箱)高性能網(wǎng)絡(luò)方案,為AIGC業(yè)務(wù)打通“任督二脈”,助力算力突飛猛進(jìn)。
銳捷網(wǎng)絡(luò)DDC產(chǎn)品連接方式示意圖
以ChatGPT為例,在算力方面,使用微軟Azure AI超算基礎(chǔ)設(shè)施(由10000塊 V100 GPU組成的高帶寬集群)上進(jìn)行訓(xùn)練,總算力消耗約3640PF-days(即每秒一千萬(wàn)億次計(jì)算,運(yùn)行3640天),這里做個(gè)公式換算一下10000塊V100需要訓(xùn)練多久:

ChatGPT算力和訓(xùn)練時(shí)間表
注:ChatGPT算力需求為網(wǎng)上獲取,在此僅供參考。OpenAI 在他們的文章“AI and Compute”中假設(shè)利用率為 33%。NVIDIA、斯坦福和微軟的一組研究人員在分布式系統(tǒng)上訓(xùn)練大型語(yǔ)言模型的利用率達(dá)到了 44% 到 52%。

ChatGPT關(guān)于訓(xùn)練時(shí)間的回答
根據(jù)ChatGPT的回復(fù)來(lái)看,比較符合上面表格計(jì)算出來(lái)的時(shí)間,利用率應(yīng)該會(huì)在50%左右。
可以看出影響一個(gè)模型的訓(xùn)練時(shí)長(zhǎng)主要因素在于GPU的利用率,以及GPU集群處理能力。而這些關(guān)鍵指標(biāo)又與網(wǎng)絡(luò)效率密切相關(guān)。網(wǎng)絡(luò)效率是影響AI集群中GPU利用率的一個(gè)重要因素。在AI集群中,GPU通常是計(jì)算節(jié)點(diǎn)的核心資源,因?yàn)樗鼈兛梢愿咝У靥幚泶笠?guī)模的深度學(xué)習(xí)任務(wù)。然而,GPU的利用率受到多個(gè)因素的影響,其中網(wǎng)絡(luò)效率是一個(gè)關(guān)鍵因素。
網(wǎng)絡(luò)在AI訓(xùn)練中扮演著至關(guān)重要的角色。AI集群通常由多個(gè)計(jì)算節(jié)點(diǎn)和存儲(chǔ)節(jié)點(diǎn)組成,這些節(jié)點(diǎn)需要頻繁地進(jìn)行通信和數(shù)據(jù)交換。如果網(wǎng)絡(luò)效率低下,這些節(jié)點(diǎn)之間的通信將會(huì)變得緩慢,這將直接影響到AI集群的算力。
低效的網(wǎng)絡(luò)可能導(dǎo)致以下問(wèn)題,從而降低GPU利用率:
數(shù)據(jù)傳輸時(shí)間增加:在低效的網(wǎng)絡(luò)中,數(shù)據(jù)傳輸?shù)臅r(shí)間將會(huì)增加。當(dāng)GPU需要等待數(shù)據(jù)傳輸完成后才能進(jìn)行計(jì)算時(shí),GPU利用率將會(huì)降低;
網(wǎng)絡(luò)帶寬瓶頸:在AI集群中,GPU通常需要頻繁地與其他計(jì)算節(jié)點(diǎn)進(jìn)行數(shù)據(jù)交換。如果網(wǎng)絡(luò)帶寬不足,GPU將無(wú)法獲得足夠的數(shù)據(jù)進(jìn)行計(jì)算,從而導(dǎo)致GPU利用率降低;
任務(wù)調(diào)度不均衡:在低效的網(wǎng)絡(luò)中,任務(wù)可能會(huì)被分配到與GPU不同的計(jì)算節(jié)點(diǎn)上。當(dāng)需要大量的數(shù)據(jù)傳輸時(shí),這可能會(huì)導(dǎo)致GPU閑置等待,從而降低GPU利用率。
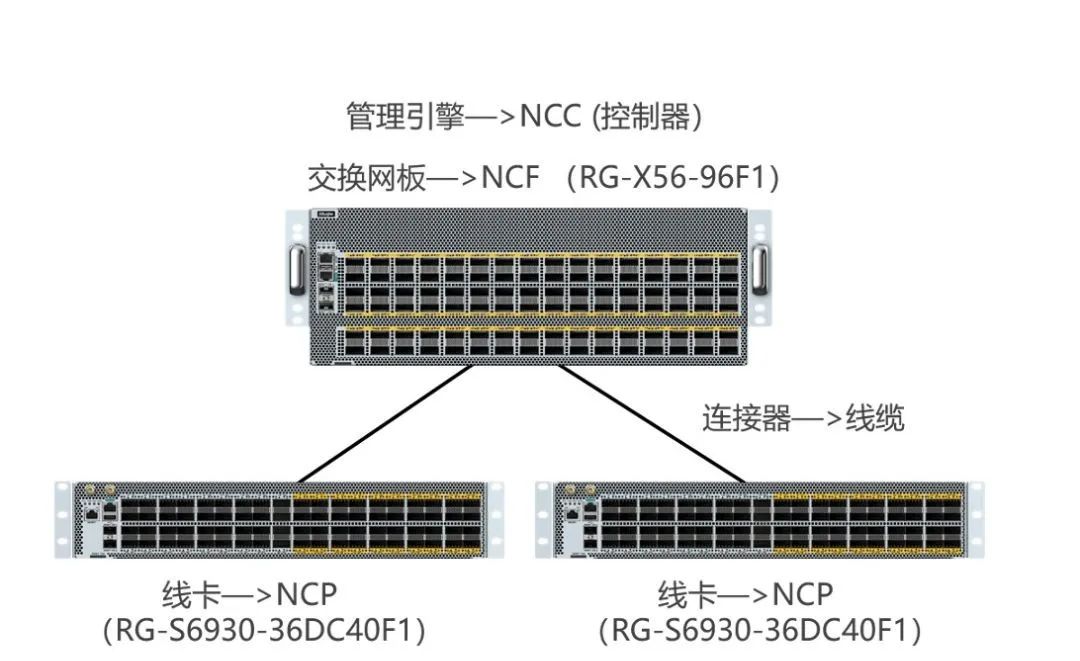
為了提高GPU利用率,需要優(yōu)化網(wǎng)絡(luò)效率。這可以通過(guò)采用更快的網(wǎng)絡(luò)技術(shù)、優(yōu)化網(wǎng)絡(luò)拓?fù)浣Y(jié)構(gòu)、合理配置帶寬等方法來(lái)實(shí)現(xiàn)。在訓(xùn)練模型中,分布式訓(xùn)練的并行度:數(shù)據(jù)并行、張量并行與流水并行決定了GPU處理的數(shù)據(jù)之間的通信模型。模型之間的通信效率受到以下幾個(gè)因素的影響:
影響通信的因素
其中,帶寬和設(shè)備轉(zhuǎn)發(fā)時(shí)延受到硬件限制,端處理時(shí)延受技術(shù)選擇(TCP or RDMA)影響,RDMA會(huì)更低,排隊(duì)和重傳則受到網(wǎng)絡(luò)優(yōu)化和技術(shù)選擇的影響。
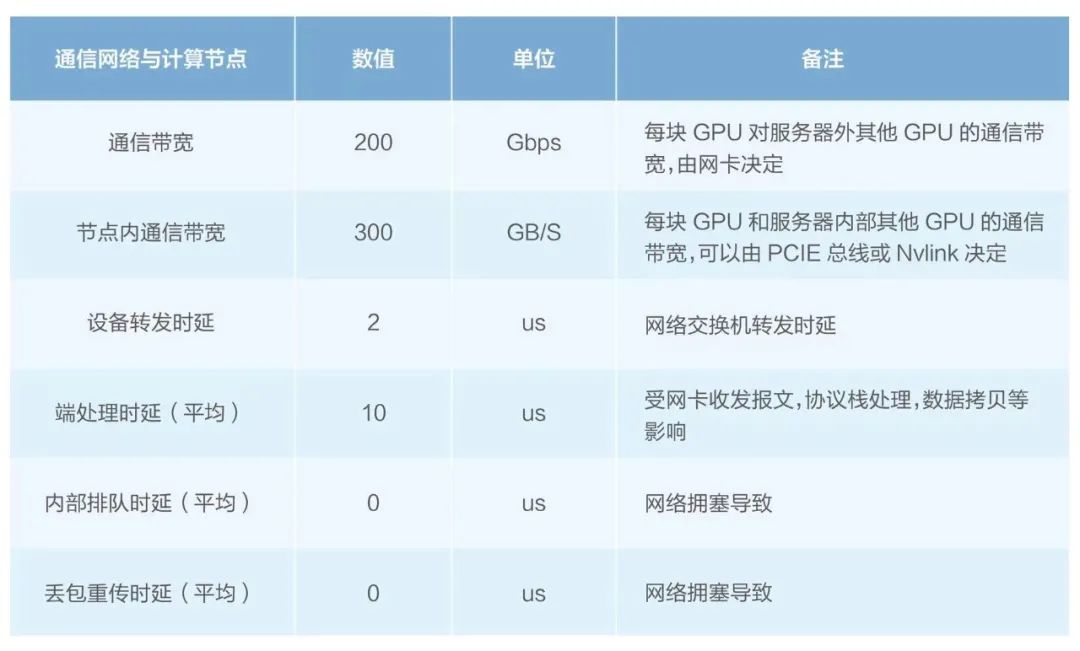
根據(jù)量化模型[1]:GPU利用率 = GPU內(nèi)迭代計(jì)算時(shí)間/(GPU內(nèi)迭代計(jì)算時(shí)間+網(wǎng)絡(luò)總體通信時(shí)間)來(lái)計(jì)算得出以下結(jié)論:
帶寬吞吐與GPU利用率的曲線圖 動(dòng)態(tài)時(shí)延和GPU利用率的曲線圖
可以看到網(wǎng)絡(luò)帶寬吞吐、動(dòng)態(tài)時(shí)延(擁塞/丟包)對(duì)GPU利用率影響明顯。
根據(jù)通信總時(shí)延的構(gòu)成來(lái)看:
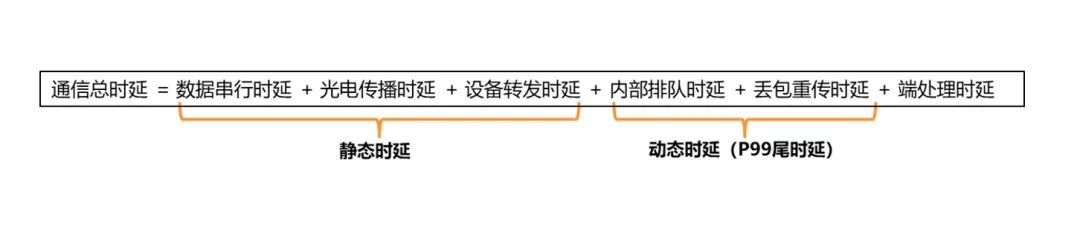
通信總時(shí)延構(gòu)成圖
靜態(tài)時(shí)延相較之下影響更小,所以更應(yīng)該著重去考慮如何減少動(dòng)態(tài)時(shí)延,這樣可以有效的提升GPU的利用率,從而達(dá)到提升算力的目標(biāo)。
Infiniband組網(wǎng)是當(dāng)前高性能網(wǎng)絡(luò)的效果最優(yōu)解,利用超高帶寬和基于Credit的機(jī)制確保無(wú)擁塞和超低時(shí)延,但是也是最昂貴的解法,相比同帶寬下傳統(tǒng)以太網(wǎng)的組網(wǎng)會(huì)貴數(shù)倍。同時(shí)Infiniband技術(shù)封閉,業(yè)內(nèi)目前成熟供應(yīng)商僅1家,對(duì)于最終用戶(hù)來(lái)說(shuō),無(wú)法實(shí)現(xiàn)第二貨源。
所以業(yè)內(nèi)大多數(shù)用戶(hù)會(huì)選擇傳統(tǒng)以太網(wǎng)組網(wǎng)的方案。
當(dāng)前高性能網(wǎng)絡(luò)主流組網(wǎng)方案是基于RoCE v2來(lái)組建支持RDMA的網(wǎng)絡(luò)。其中重要的兩項(xiàng)搭配技術(shù)是PFC和ECN,兩者均是為了避免鏈路中的擁塞而產(chǎn)生的技術(shù)。
多級(jí)PFC組網(wǎng)下會(huì)針對(duì)交換機(jī)入口(Ingress)擁塞,逐級(jí)反壓到源端服務(wù)器暫停發(fā)送,緩解網(wǎng)絡(luò)擁塞,規(guī)避丟包;但該方案在多級(jí)組網(wǎng)下可能會(huì)面臨PFC Deadlock導(dǎo)致RDMA流量停止轉(zhuǎn)發(fā)的風(fēng)險(xiǎn)。
圖片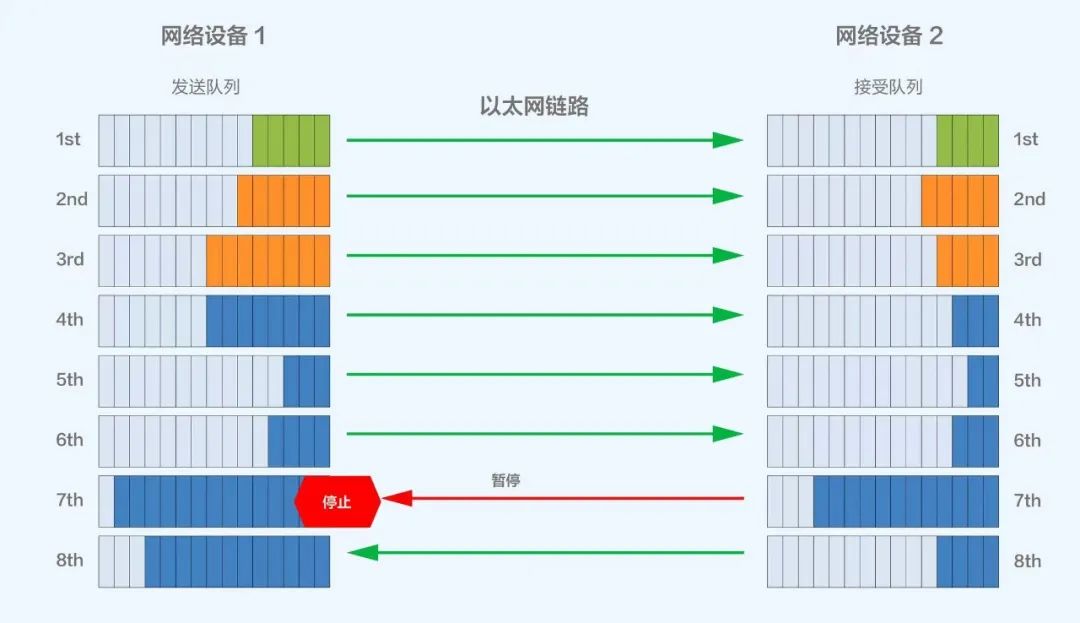
PFC工作機(jī)制示意圖
而ECN則會(huì)基于對(duì)交換機(jī)出口(Egress)擁塞的目的端感知,直接生成一個(gè)RoCEv2 CNP包通知源端降速,源服務(wù)器收到CNP報(bào)文,精準(zhǔn)降低對(duì)應(yīng)QP的發(fā)送速率,緩解擁塞的同時(shí)避免無(wú)差別降速。
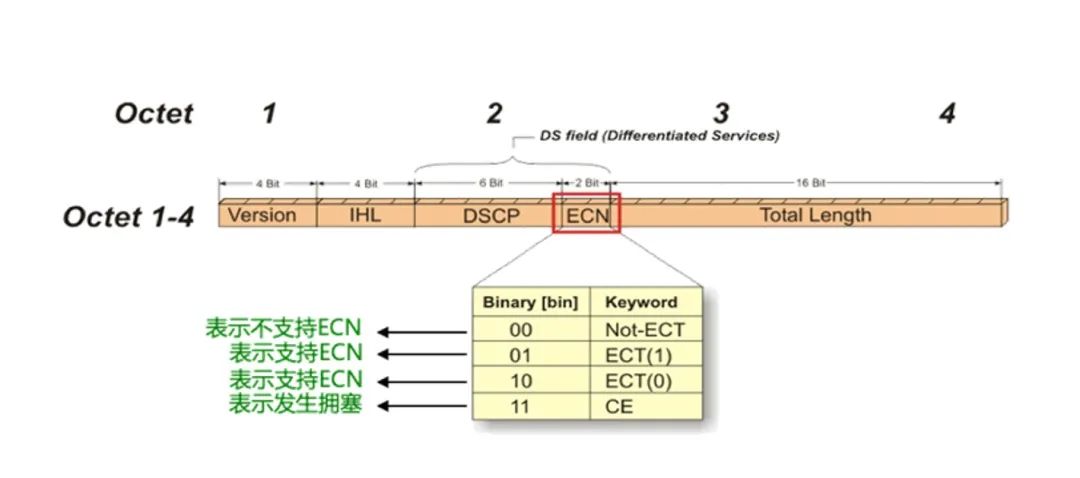
ECN標(biāo)記位示意圖
這兩項(xiàng)技術(shù)本身并沒(méi)有什么問(wèn)題,都是為了解決擁塞而誕生的技術(shù),但是采用這種技術(shù)后可能會(huì)被網(wǎng)絡(luò)中可能產(chǎn)生的擁塞而頻繁觸發(fā),最終會(huì)導(dǎo)致源端暫停或降速發(fā)送,通信帶寬會(huì)降低,會(huì)對(duì)GPU利用率產(chǎn)生比較大的影響,從而造成整個(gè)高性能網(wǎng)絡(luò)的算力被拉低。
在AI訓(xùn)練計(jì)算中會(huì)有All-Reduce和All-to-All兩種主要的模型,兩種模型都需要頻繁的從一個(gè)GPU到另外多個(gè)GPU進(jìn)行通信。
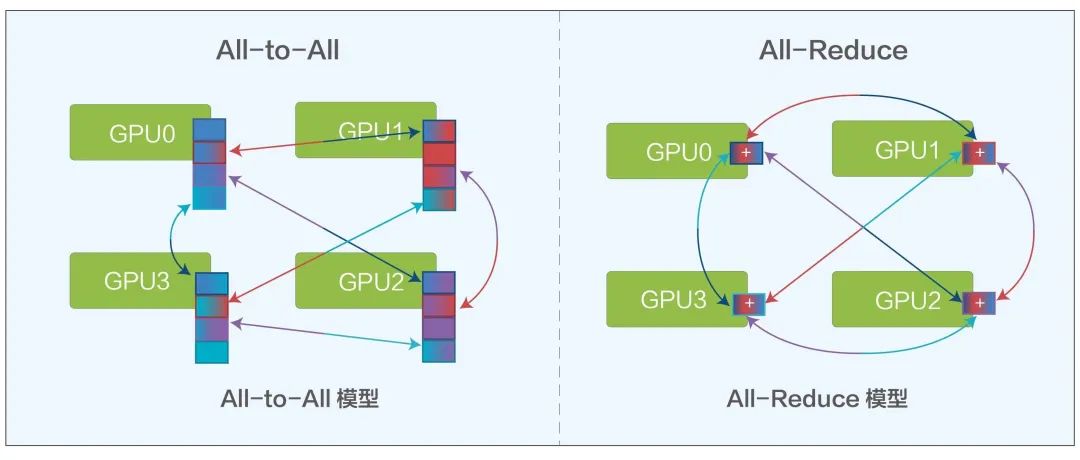
All-to-All模型 All-Reduce模型
在傳統(tǒng)組網(wǎng)下,ToR和Leaf設(shè)備采用路由+ECMP的組網(wǎng)模式,ECMP會(huì)基于流進(jìn)行哈希負(fù)載選路,有一種極端情況就是某一條ECMP鏈路因?yàn)橐粭l大象流而跑滿,其余多條ECMP鏈路相對(duì)空閑,造成負(fù)載不均的情況。
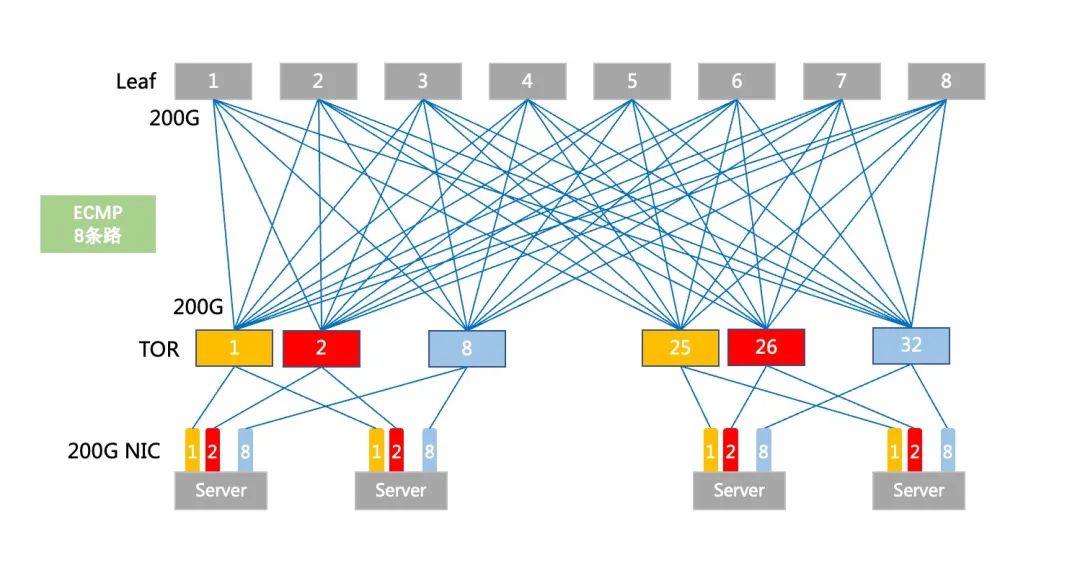
傳統(tǒng)ECMP部署圖
在內(nèi)部模擬8條ECMP鏈路的測(cè)試環(huán)境下,測(cè)試結(jié)果如下:
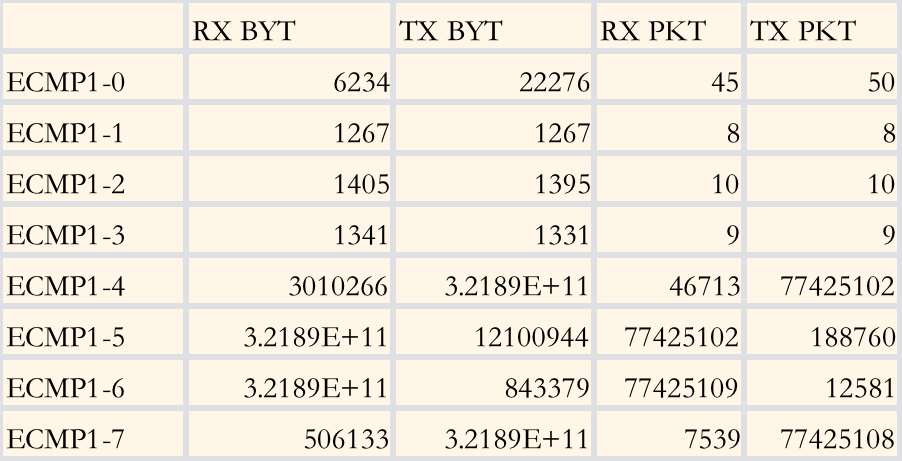
ECMP流量測(cè)試結(jié)果
可以看出,基于流的ECMP會(huì)造成較明顯的某幾條鏈路占用(ECMP1-5和1-6)和空閑(ECMP1-0至1-3較空閑),而在All-Reduce和All-to-All的兩種模型下, 就很容易造成一條路線因?yàn)镋CMP的負(fù)載不均而擁塞,一旦擁塞造成重傳,就會(huì)提升總體的通信總時(shí)延,從而降低GPU利用率。
所以,為了解決此類(lèi)問(wèn)題,研究界提出了phost、Homa、NDP、1RMA 和 Aeolus等豐富的解決方案,它們?cè)诓煌潭壬辖鉀Q了 incast, 還解決了負(fù)載平衡和低延遲請(qǐng)求/響應(yīng)流量的問(wèn)題。但是也帶來(lái)了新的挑戰(zhàn),往往這些研究的方案都是需要端到端來(lái)解決問(wèn)題,對(duì)主機(jī)、網(wǎng)卡、網(wǎng)絡(luò)的改動(dòng)較大,對(duì)于一般用戶(hù)而言,成本較高。
海外有部分互聯(lián)網(wǎng)公司寄希望于利用采用DNX芯片支持VOQ技術(shù)的框式交換機(jī)來(lái)解決負(fù)載不均衡帶來(lái)的帶寬利用率低的問(wèn)題,但也面臨以下幾個(gè)挑戰(zhàn)。
擴(kuò)展能力一般,機(jī)框大小限制了最大端口數(shù),如想做更大規(guī)模的集群,需要橫向擴(kuò)展多個(gè)機(jī)框,也會(huì)產(chǎn)生多級(jí)PFC和ECMP的鏈路,所以框只適合于小規(guī)模部署;
設(shè)備功耗大,機(jī)框內(nèi)線卡芯片、Fabric芯片、風(fēng)扇等數(shù)量眾多,單設(shè)備的功耗極大,輕松超過(guò)2萬(wàn)瓦,有的甚至3萬(wàn)多瓦,對(duì)機(jī)柜電力要求高;
單設(shè)備端口數(shù)量多,故障域大。
所以基于以上原因,框式設(shè)備只適合小規(guī)模部署AI計(jì)算集群。
DDC是一種分布式解耦機(jī)框設(shè)備的解決方案,采用的芯片和關(guān)鍵技術(shù)與傳統(tǒng)框式交換機(jī)幾乎相同,但DDC架構(gòu)簡(jiǎn)單支持彈性擴(kuò)展和功能快速迭代、更易部署、單機(jī)功耗低。
如下圖所示,業(yè)務(wù)線卡作為前端成為NCP角色,交換網(wǎng)板作為后端成為NCF角色,原先兩者之間的連接器組件現(xiàn)在被光纖線纜代替,原有框式設(shè)備的管理引擎在DDC架構(gòu)中也成為了NCC集中/分布式的管理組件。
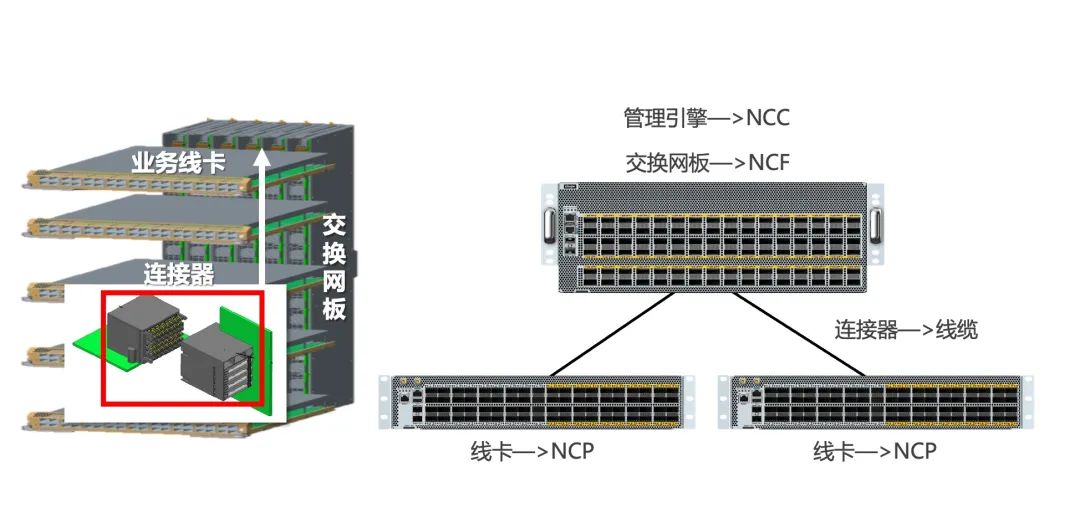
DDC產(chǎn)品連接方式示意圖
DDC架構(gòu)相較于框式架構(gòu)的優(yōu)勢(shì)在于可以提供彈性可擴(kuò)展性,組網(wǎng)規(guī)模可以根據(jù)AI集群大小來(lái)靈活選擇。
單POD組網(wǎng)中,采用96臺(tái)NCP作為接入,其中NCP下行共36個(gè)200G接口,負(fù)責(zé)連接AI計(jì)算集群的網(wǎng)卡。上行共40個(gè)200G接口最大可以連接40臺(tái)NCF,NCF提供96個(gè)200G接口,該規(guī)模上下行帶寬為超速比1.1:1。整個(gè)POD可支撐3456個(gè)200G網(wǎng)絡(luò)接口,按照一臺(tái)服務(wù)器配8塊GPU來(lái)計(jì)算,可支撐432臺(tái)AI計(jì)算服務(wù)器。
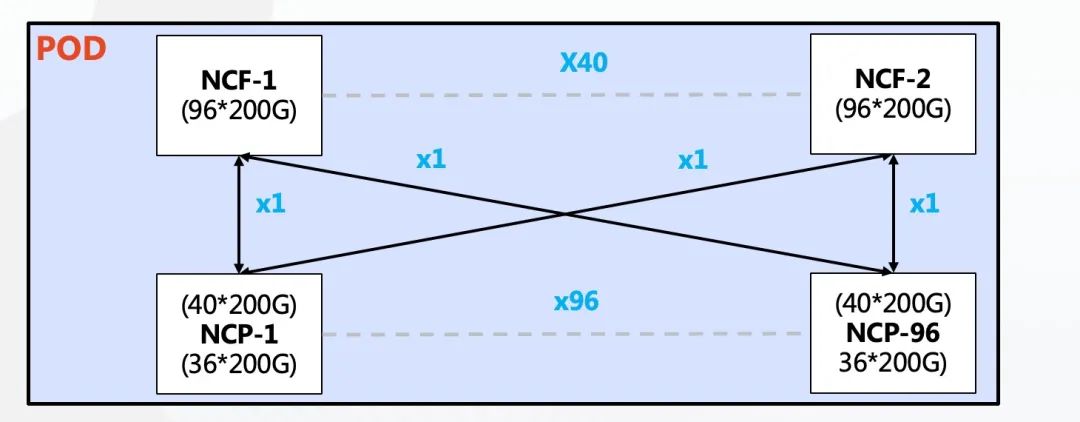
單POD組網(wǎng)架構(gòu)圖
多級(jí)POD組網(wǎng)中,可以實(shí)現(xiàn)基于POD的按需建設(shè)。因?yàn)樵搱?chǎng)景POD中NCF設(shè)備要犧牲一半的SerDes用于連接第二級(jí)的NCF,所以此時(shí)單POD采用48臺(tái)NCP作為接入,下行共36個(gè)200G接口,單POD內(nèi)可以支撐1728個(gè)200G接口。通過(guò)橫向增加POD實(shí)現(xiàn)規(guī)模的擴(kuò)容,整體最大可支撐10368多個(gè)200G網(wǎng)絡(luò)端口。
NCP上行40個(gè)200G接POD內(nèi)40臺(tái)NCF,POD內(nèi)NCF采用48個(gè)200G接口下行,48個(gè)200G接口分為16個(gè)一組上行到第二級(jí)的NCF。第二級(jí)NCF采用40個(gè)平面,每個(gè)平面3臺(tái)的設(shè)計(jì),分別對(duì)應(yīng)在POD內(nèi)的40臺(tái)NCF。
整個(gè)網(wǎng)絡(luò)的POD內(nèi)實(shí)現(xiàn)了超速比1.1:1,而在POD和二級(jí)NCF之間實(shí)現(xiàn)了1:1的收斂比。

200G的網(wǎng)絡(luò)端口兼容100G網(wǎng)卡接入,特殊情況下可利用1分2或1分4線纜兼容25/50G網(wǎng)卡。
依托分片后的Cells轉(zhuǎn)發(fā)機(jī)制進(jìn)行動(dòng)態(tài)負(fù)載均衡,實(shí)現(xiàn)延遲的穩(wěn)定性,降低了不同鏈路的帶寬峰值差。
轉(zhuǎn)發(fā)流程如圖所示:
首先發(fā)送端從網(wǎng)絡(luò)中接收數(shù)據(jù)包并分類(lèi)到VOQs中存儲(chǔ),在發(fā)送數(shù)據(jù)包之前會(huì)先發(fā)送Credit報(bào)文確定接收端是否有足夠的緩存空間處理這些報(bào)文;
如果可以則將數(shù)據(jù)包分片成Cells并且動(dòng)態(tài)負(fù)載均衡到中間的Fabric節(jié)點(diǎn)。這些Cells在接收端會(huì)進(jìn)行重組和存儲(chǔ),進(jìn)而轉(zhuǎn)發(fā)到網(wǎng)絡(luò)中。

Cells是基于數(shù)據(jù)包的切片技術(shù),一般大小為 64-256Byte。
切片后的Cells根據(jù)reachability table 中 cell destination 的查詢(xún)來(lái)決定如何轉(zhuǎn)發(fā),并采用輪詢(xún)的機(jī)制發(fā)送。這樣做的好處相比ECMP按流進(jìn)行哈希計(jì)算后選擇某一條路的模式,切片后的Cells負(fù)載會(huì)充分利用到每一條上行鏈路,所有上行鏈路的傳輸數(shù)據(jù)量會(huì)近似相等。

如果接收端暫時(shí)沒(méi)能力處理報(bào)文,報(bào)文會(huì)在發(fā)送端的VOQ中暫存,并不會(huì)直接轉(zhuǎn)發(fā)到接收端導(dǎo)致丟包問(wèn)題的產(chǎn)生,每片DNX芯片可以提供芯片內(nèi)OCB緩存以及片外8GB的HBM高速緩存,對(duì)200G端口相當(dāng)于可以緩存150ms左右的數(shù)據(jù)。只有當(dāng)對(duì)端Credit報(bào)文明確可以接受時(shí)才會(huì)發(fā)送。這樣的機(jī)制下,充分利用緩存可以大幅度減少丟包,甚至不會(huì)產(chǎn)生丟包情況。減少數(shù)據(jù)重傳,整體通信時(shí)延更穩(wěn)定更低,從而可以提高帶寬利用率,進(jìn)而提升業(yè)務(wù)吞吐效率。

按照DDC的邏輯來(lái)看,所有NCP和NCF可以看成一臺(tái)設(shè)備,所以在此網(wǎng)絡(luò)中部署RDMA域后,只在針對(duì)服務(wù)器的接口處存在1級(jí)的PFC,不會(huì)像傳統(tǒng)網(wǎng)絡(luò)一樣產(chǎn)生多級(jí)PFC的壓制與死鎖。另外根據(jù)DDC的數(shù)據(jù)轉(zhuǎn)發(fā)機(jī)制,可在接口處部署ECN,一旦在內(nèi)部的Credit和緩存機(jī)制無(wú)法支撐突發(fā)流量,可以向服務(wù)器端發(fā)送CNP報(bào)文要求降速(通常情況下在AI的通信模型下,All-to-All和All-Reduce+Cell切片可以將流量盡可能的均衡,很難出現(xiàn)1個(gè)端口被打滿的情況,所以ECN在多數(shù)情況可以不配置)。

在管理控制平面上,為了解決管理網(wǎng)故障以及NCC單點(diǎn)故障的影響,我們?nèi)∠薔CC的集中控制面,構(gòu)建了分布式OS,通過(guò)SDN運(yùn)維控制器通過(guò)標(biāo)準(zhǔn)接口(Netconf、GRPC等)配置管理設(shè)備,每臺(tái)NCP和NCF獨(dú)立管理,有獨(dú)立的控制面和管理面。
從方案理論上說(shuō),DDC擁有支持彈性擴(kuò)展和功能快速迭代、更易部署、單機(jī)功耗低等眾多優(yōu)勢(shì);但從實(shí)際角度出發(fā),傳統(tǒng)組網(wǎng)也擁有諸如市面可選品牌和產(chǎn)品路線較多、可支撐更大規(guī)模的集群等技術(shù)成熟帶來(lái)的優(yōu)勢(shì)。因此在客戶(hù)面臨項(xiàng)目需求時(shí)究竟是選擇更高性能的DDC,還是更大規(guī)模部署的傳統(tǒng)組網(wǎng),可以參考下面的對(duì)比及測(cè)試結(jié)果:
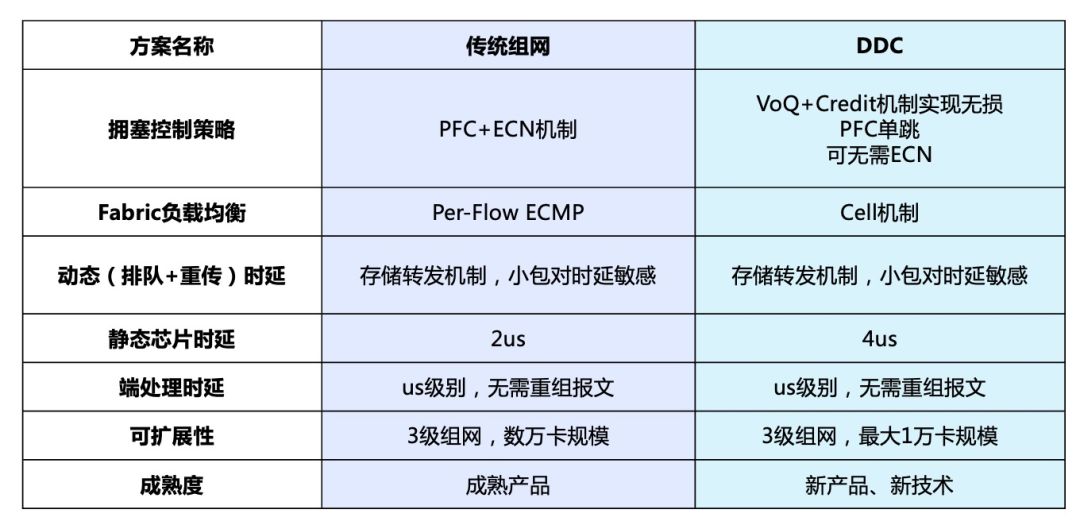
傳統(tǒng)組網(wǎng)與DDC測(cè)試對(duì)比結(jié)果圖
同時(shí)我們使用OpenMPI測(cè)試套件進(jìn)行了框式設(shè)備(框式設(shè)備和DDC原理相同,本次采用框式測(cè)試)和傳統(tǒng)組網(wǎng)設(shè)備的對(duì)比模擬測(cè)試,結(jié)論是在All-to-All場(chǎng)景下,相較于傳統(tǒng)的組網(wǎng),框式設(shè)備帶寬利用率提升約20%(對(duì)應(yīng)GPU利用率提升8%左右)。
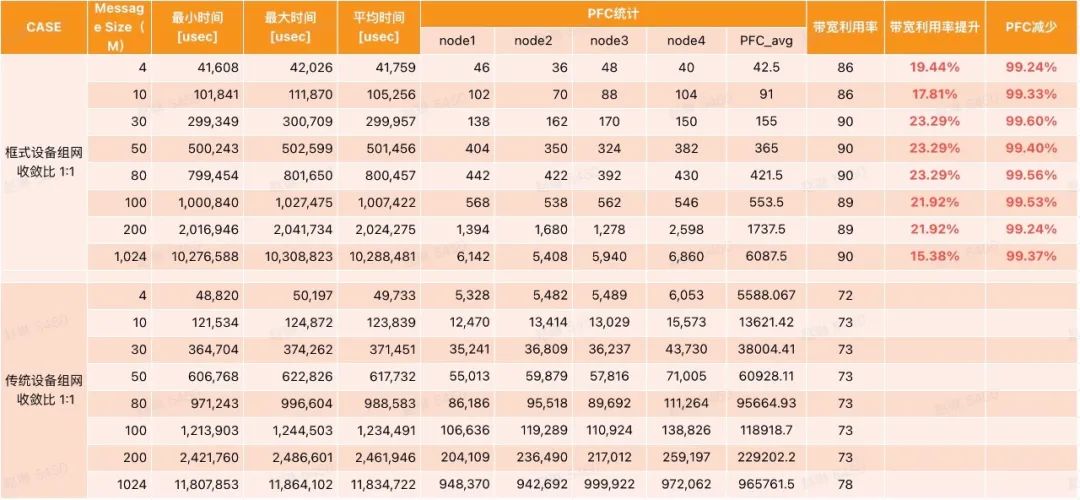
框式設(shè)備和傳統(tǒng)組網(wǎng)設(shè)備的對(duì)比模擬測(cè)試
基于對(duì)客戶(hù)需求的深刻理解,銳捷網(wǎng)絡(luò)已經(jīng)率先推出了兩款可交付產(chǎn)品,分別是200G NCP交換機(jī)和200G NCF交換機(jī)。
該交換機(jī)2U高度,提供36個(gè)200G的面板口,40個(gè)200G的Fabric內(nèi)聯(lián)口,4個(gè)風(fēng)扇和2個(gè)電源。
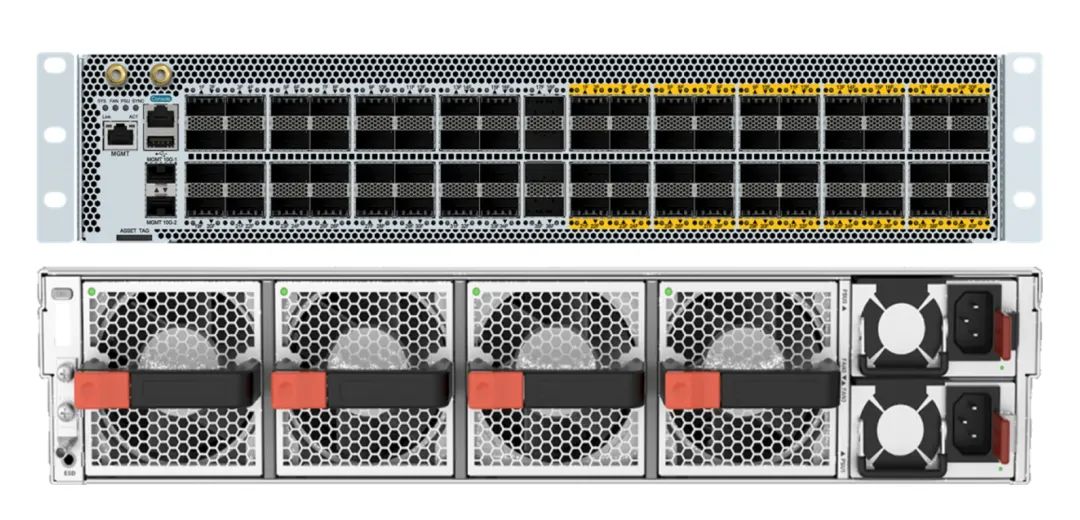
該交換機(jī)4U高度,提供96個(gè)200G的Fabric內(nèi)聯(lián)口,8個(gè)風(fēng)扇和4個(gè)電源。

未來(lái)銳捷網(wǎng)絡(luò)還會(huì)繼續(xù)研發(fā)、推出400G端口形態(tài)產(chǎn)品,敬請(qǐng)期待。
銳捷網(wǎng)絡(luò)(證券代碼:301165)作為行業(yè)領(lǐng)導(dǎo)者,一直致力于提供高品質(zhì)、高可靠性的網(wǎng)絡(luò)設(shè)備和解決方案,以滿足客戶(hù)對(duì)于智算中心不斷提高的需求。在推出“智速“DDC解決方案的同時(shí),銳捷網(wǎng)絡(luò)也在積極探索和開(kāi)發(fā)傳統(tǒng)組網(wǎng)中的端網(wǎng)優(yōu)化方案,通過(guò)充分利用服務(wù)器智能網(wǎng)卡搭配網(wǎng)絡(luò)設(shè)備協(xié)議的優(yōu)化,實(shí)現(xiàn)整網(wǎng)帶寬利用率提升,幫助客戶(hù)更快迎來(lái)AIGC智算時(shí)代。
參考文獻(xiàn):
[1]Deepak Narayanan, Mohammad Shoeybi, Jared Casper,Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM,arXiv:2104.04473v5 [cs.CL] 23 Aug 2021

 文檔評(píng)價(jià)
文檔評(píng)價(jià)



















