 發布時間:2024-03-13
發布時間:2024-03-13

(作者|賈桂鵬)
當下,AI大模型的參數已升級至萬億級別,各個大模型龐大的訓練任務需要由大量GPU服務器組成的算力集群來協作完成。同時算力的提升對網絡提出了超大規模、超高帶寬、超強可靠性的需求,為AI模型訓練提供強有力的支持。

面對AI浪潮,各個行業紛紛搶灘布局,熱度急劇升溫,同時在我國“新基建”“東數西算”等工程的加持下,算力網絡這條全新賽道涌進越來越多的參與者。據Dell'Oro Group最新報告顯示,到2027年20%的以太網數據中心交換機端口將連接到加速服務器,以支持AI的工作負載。
隨著新的生成式AI應用的興起,預計推動數據中心網絡市場未來五年銷量累計收入超過1000億美元。算力基礎設施和網絡基礎設施的整體布局與技術架構迎來革命性變化,“算”“網”基礎設施成為算力產業發展的關鍵所在,其迭代演進亟須加速。
在此背景下,元宇宙新聲有機會采訪到銳捷網絡數據中心網絡事業群DCN BU總經理黃米青,與他一起探討了AIGC技術發展為企業帶來了怎樣的改變,銳捷網絡智算中心如何賦能企業數字化發展。

(銳捷網絡數據中心網絡事業群DCN BU總經理 黃米青)
成立于2003年的銳捷網絡,跟隨著數字經濟持續加速發展馭風而行,深耕網絡設備、網絡安全產品及云桌面解決方案三大領域,憑借強大的研發創新實力、貼近用戶的產品方案以及專業快捷的服務能力,現已發展成為ICT及云計算基礎設施專業企業。根據IDC中國以太網交換機市場跟蹤報告2023Q3數據分析顯示,銳捷網絡數據中心交換機在互聯網行業市場份額排名前列。
而在AI時代,我們也看到銳捷網絡繼續秉承著創新發展的路徑,憑借敏銳的行業洞察與深厚的技術積淀,進一步推動行業發展,行穩而致遠。
目前,許多企業數字化轉型已進入“深水區”,數字技術與傳統行業的簡單疊加,已不能滿足傳統垂直行業的發展需求,企業在各自領域面臨新機遇和新挑戰,急需向廣度和深度進發。
生成式AI作為當前新興的人工智能技術發展趨勢,是企業加速數字化轉型的重要選擇之一。部分行業代表性企業已在生產運營中部署應用生成式AI,取得了初步成效。

黃米青認為:“AI技術對于企業發展來說是非常重要的機會。”
首先,這些技術能夠幫助企業實現自動化和智能化,提高生產效率、降低成本;其次,這些技術還能為企業帶來更豐富、更個性化的用戶體驗。
黃米青表示:“AI的普及和深化將可能從以下幾個方面深刻改變人類生活:智能家居、健康醫療、智能交通、工作助手、虛擬娛樂、人類增強等等。這些都將讓我們的生活更加便利和舒適。進而,還將影響到社會的方方面面,包括經濟結構、勞動力市場、城市規劃、法律法規乃至倫理道德觀念。”

那么,對于更多希望加快數字化轉型步伐的企業而言,下一步應該如何用上、用好生成式人工智能呢?
首先要做到價值認同。要讓數字化轉型成為企業管理者與企業員工的共識,要充分認識、認可生成式人工智能。生成式AI能夠在客戶服務、銷售市場、知識管理以及輔助決策方面助力企業實現大幅降本增效、降低商業試錯成本。
在AI商業繁榮的大趨勢下,生成式人工智能正變得更加普惠,企業使用成本持續降低,企業員工學習門檻持續降低。
其次要找到“正確路徑”。對于企業而言,選擇使用大模型和生成式AI來提升數字化能力,需要遵循科學的理論方法。企業需要根據自身的行業特點和專業知識,與基礎大模型合作,將特定場景的專業數據加入基礎大模型進行再訓練和微調,研發出專屬大模型或場景大模型。
再次要防范風險。生成式AI作為一種新興的技術,在賦能產業高質量發展的同時,也存在許多風險,如隱私保護、結果失控、數據泄露等。

另外,元宇宙新聲認為,上述一切的發展前提是算力的發展,我們要考量算力是否能夠滿足人工智能的需求,因此,如何在AI服務這個業務模式中保持強有力的競爭力,提升集群的GPU效率變得尤為關鍵。
隨著生成式AI的發展,以及大模型參數量的提升,對算力的消耗也在明顯增加。大模型訓練對于算力的需求也符合類似“摩爾定律”的特征,從每3-4個月算力消耗翻倍到每2個月算力消耗翻倍。隨著模型迭代速度越來越快,對算力的需求也越發緊迫。
以ChatGPT為例,從OpenAI的官方聲明可以看出,ChatGPT4的規模遠遠超過了ChatGPT3,并且使用更強大的硬件GPU(H100)。這意味著ChatGPT4的訓練時間和計算成本都非常高,需要更多的時間和資源來完成。
可以看出影響一個模型的訓練時長主要因素在于GPU的利用率,以及GPU集群處理能力,而這些關鍵指標又與網絡效率密切相關。網絡效率是影響AI集群中GPU利用率的一個重要因素。
在AI集群中,GPU通常是計算節點的核心資源,因為它們可以高效地處理大規模的深度學習任務。然而,GPU的利用率受到多個因素的影響,其中網絡效率是一個關鍵因素。

眾所周知,AI集群通常由多個計算節點和存儲節點組成,這些節點需要頻繁地進行通信和數據交換,如果網絡效率低下,這些節點之間的通信將會變得緩慢,這將直接影響到AI集群的算力。
黃米青表示:“企業要將更多資源投入到提升算力使用效率上,其中包括模型及并行通信算法的研發以及高效算力網絡的構建。”
但是,我們看到影響網絡通信效率的因素拋開硬件性能的限制,針對端處理時延、內部排隊時延和丟包重傳時延三大動態因素優化網絡擁塞和時延,則成為提升AI集群網絡通信性能具備成本效益的方法。基于這些思考,銳捷網絡致力于提升通信帶寬利用率,降低動態時延以及實現無損的網絡傳輸,以提升AI集群網絡通信性能。
在此背景下,銳捷網絡面向下一代AI云服務的智算中心網絡建設,推出了銳捷網絡AI-FlexiForce智算中心網絡解決方案。那么它又有怎樣的價值呢?
銳捷網絡發布的AI-FlexiForce智算中心網絡解決方案,采用NCP+NCF為基礎模塊橫向擴展的三級網絡架構,并基于高性能芯片技術,通過將數據流切分成等長的Cell并負載到所有鏈路,提升網絡帶寬利用率;基于VOQ+Credit的端到端流控機制實現與業務無關的無損自閉環網絡,助力業務算力提升。
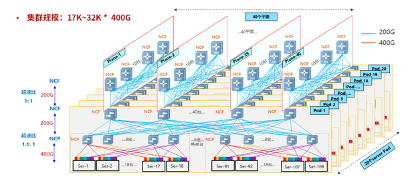
從規模上來看,AI-FlexiForce智算中心網絡解決方案采用三級組網,可支持17k到32k個400G的端口。銳捷網絡在國內首發了400G的NCP和NCF設備,以支持AIGC網絡的大接入帶寬。NCP設備RG-S6930-18QC40F1,支持18口400G的業務口,并支持40口200G的Fabric內聯口,用于和NCP之間的互聯。NCF設備RG-X56-96F1,支持96口200G的Fabric內聯口。我們可以看到,該解決方案可滿足不同業務需求,具有可擴展性和靈活性。

黃米青表示:“銳捷AI-FlexiForce智算中心網絡解決方案通過創新性地應用鏈路負載和擁塞控制技術,解決網絡中的擁塞沖突問題,提升GPU之間通信效率,進而提升GPU計算效率,加速企業大模型應用的推出。”
而且,在研發AI-FlexiForce智算中心網絡解決方案的同時,銳捷網絡還打造了分布式OS,旨在簡化部署,提高系統可靠性。傳統的DDC(Distributed Disaggregated Chassis,分布式分散式機箱)由于控制面集中,一旦NCC(Network Cloud Controller網絡云控制器)失聯,就會影響整個網絡,從而影響整個業務流程。另外,由于版本不兼容,如果部分設備需要升級,就會面臨巨大的運維難題。
銳捷網絡AI-FlexiForce智算中心網絡解決方案采用去中心化的分布式OS,實現了控制面與管理面解耦。即使管理平臺出現問題,也不會影響整個網絡的運行。與此同時,它還解決了兼容性問題,設備可以獨立升級,大幅降低了運維難度。
黃米青解釋道:“我們在研發AI-FlexiForce智算中心網絡解決方案時,打造了分布式OS,意在實現分布式方案架構的統一管理基礎上,盡可能降低系統性風險,提升AI訓練網絡的長期穩定運行。”
而在談到銳捷智算中心的優勢時,黃米青表示:“銳捷擁有RALB、AILB等網絡負載均衡技術,在智算網絡方案中提供優性能。”
可以預見,未來,隨著AI對于算力需求持續增加,銳捷將持續精進AI Fabric智算中心網絡解決方案,在降低時延、提高在網計算性能、實現端網融合等方面持續突破,打造高速互聯、彈性可擴展、綠色節能的下一代AI云服務智算中心網絡。
可以預見,在全球互聯網流量不斷增長和數據應用需求日益多樣化的背景下,銳捷將持續精進AI-FlexiForce智算中心網絡解決方案,在降低時延、提高在網計算性能、實現端網融合等方面持續突破。未來,銳捷網絡還將通過持續的技術研發和產品創新,繼續為全球的數據中心提供更高效網絡解決方案,在AI時代助力各行業實現快速發展。
這是我們第一次與黃總交流,而且還是線上形式,多少會顯得有一些倉促,但我們還是在溝通的過程中明顯感受到他在專業領域上的積累,比如他對于AI在企業端價值的體現、算力在AI發展過程中的重要性等都有著非常獨到的看法和解讀,也為我們提供了很多不同角度來觀察科技的發展,這也是我們在交流過程中的收獲。
在采訪最后,當黃總在談到銳捷網絡在未來AI時代的賦能時,我們也感受到了他對于AI發展的期待和對銳捷網絡產品和解決方案的信心。我們也希望,未來銳捷網絡也能像黃總展露出的信心一樣勇往直前,利用自己技術賦能千行百業。

 文檔評價
文檔評價



















