














本文作者:墨染塵香
銳捷網絡互聯網系統部解決方案架構師
隨著互聯網業務的迅猛發展,數據中心基礎架構也在不斷向前快速迭代,隨之而來的問題是如何管理好這張龐大的數據中心網絡。本文立足于新一代25/100G數據中心架構之上,分析了目前運維層面的挑戰,提出了面向網絡運維全流程的技術升級,針對于流程中的每個環節講解了對應的運維技術。希望可以通過本文給讀者一些新的啟發和靈感。
一、新時代需要新技術
隨著云計算、AI、大數據等技術的快速發展,一些新的業務形態呈現在大家的面前,比如今年受疫情影響而爆火的在線教育,直播帶貨等。業務應用的革新得益于基礎設施的不斷發展和完善,上半年“新基建”的概念異常火爆,與之相關幾大領域的股票也都在瘋狂上漲。
2020年4月20日上午,國家發改委召開4月份例行新聞發布會,首次就“新基建”概念和內涵作出正式的解釋。
“新型基礎設施是以新發展理念為引領,以技術創新為驅動,以信息網絡為基礎,面向高質量發展需要,提供數字轉型、智能升級、融合創新等服務的基礎設施體系。”這是發改委給出的“新基建”定義。
新型基礎設施主要包括3個方面內容,即信息基礎設施、融合基礎設施以及創新基礎設施。其中信息基礎設施中的數據中心作為通信網絡和算力的基礎是我們今天要討論的重點。
在上一期的技術盛宴直播活動中已經跟大家分享了數據中心網絡架構的演進歷程,也重點介紹了新一代數據中心架構的設計建議,今天我們聚焦在運維層面來聊一聊新一代數據中心網絡運維技術。
首先作者認為運維能力和架構一樣也是需要更新迭代的,原因體現在兩個方面:
第一是業務驅動,25/100G時代的數據中心承載了一些基于RDMA技術的業務,比如高性能存儲等。這些業務對延時和丟包非常敏感,因此要求我們對網絡設備要做到更加精細化的狀態監控,由此可見傳統的SNMP技術可能將要被新的運維手段所替代。
第二是技術驅動,主流的25G數據中心架構都會采用單芯片的盒式交換機來進行集群內的組網,由于芯片選型發生了變化,因此對應的運維技術也會有一些改變。具體來說就是我們可以享受到新型芯片帶來的技術紅利,比如基于IFA(IFA,In-band Flow Analyzer)的可視化運維能力等。
綜合以上分析,作者認為新一代的數據中心需要新的運維技術來協助我們管理好這張龐大的數據中心網絡。
二、面向網絡運維全流程的技術升級
我們對很多公司的網絡架構以及運維流程做了調研和分析,總結了一些通用的問題供大家參考和討論。
標準化的運維流程大概分為五步:網絡交付,網絡配置管理,網絡監控,問題定位和故障處理。下面我們來分析一下每個流程中都有哪些問題亟待解決。
網絡交付
對于配置管理的流程大家并不陌生,SSH、Telnet等基于CLI的配置管理。但面向海量的網絡設備如果進行重復性的機械動作,往往會消耗大家比較多的精力,影響運維的效率。
網絡監控
在部署基于RDMA的業務之前,采用SNMP協議實現對網絡設備的監控是比較主流的做法;但隨著RDMA的應用越來越多,我們對網絡設備運行狀態需要掌握的更加精細和及時,而SNMP以分鐘為周期的時效性和可監控的維度、顆粒度都會顯得有些不足。
問題定位
以丟包問題為例,問題定位就是說我們知道了有丟包事件發生,需要定位出哪個包丟了,在哪里丟的,為什么丟。這些信息以前都沒有很好的技術手段來幫助我們識別。基于ECMP的組網,加上網絡設備本身又是黑盒,我們連數據包真實轉發的物理路徑都無從得知,更何況是問題定位呢。
故障處理
目前大多數運維模式都屬于救火式的被動響應,業務先報障,運維團隊接到CASE后做對應處理,對其處理的方式往往是需要依靠運維工程師的經驗。在人工智能快速發展的時代,如果還一味的依靠人工來解決問題,是不是有些不夠智能呢?
綜合以上的分析,我們在整體運維流程的基礎上進行了面向網絡運維的全方位技術升級。
在考慮成本和效率的前提下,我們在每個運維流程中都應用了新的技術來解決新時代下的新問題。
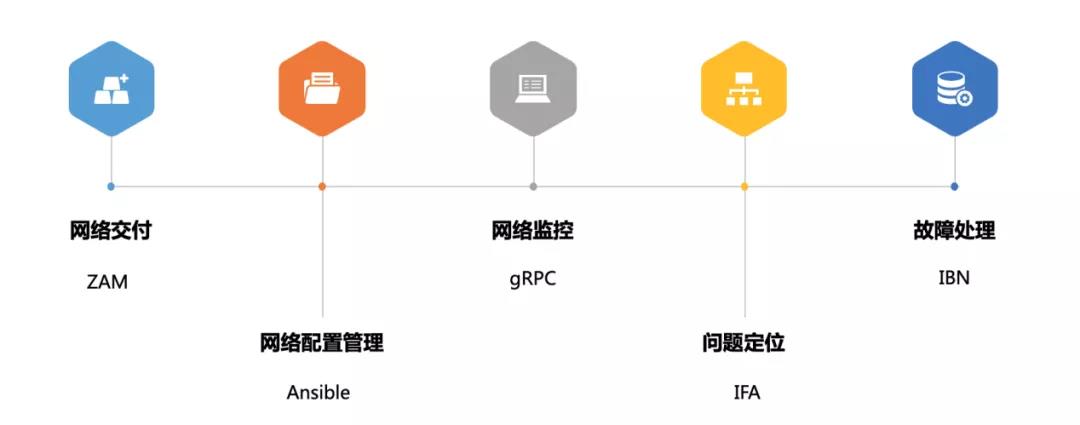
圖1 運維全流程與運維新技術的對應關系
下面我們逐一分析在不同運維流程中,我們應當采用哪些新的運維技術來幫助我們更有效地管理好這張龐大的數據中心網絡。
三、網絡上線交付
零配置自動部署管理
(ZAM,
Zero-configuration Automatic Manage)
上文提到在網絡初始化交付環節中存在大規模交付的效率問題,那么應用什么技術可以提高這項工作的效率呢?
ZAM零配置自動部署管理技術可以很好的解決這個問題。
交換機到貨安裝上架并加電后,識別到空配置會自動進入ZAM模式,通過DHCP的兩個Option字段獲取到TFTP的Server地址以及要下載的腳本文件。基于自身的SN碼獲取到屬于自身的版本、補丁、數據配置,自動重啟后,可以分鐘級完成整機房的網絡設備交付。
在網絡上線交付環節應用ZAM技術大大降低了對人的依賴,提高準確率的同時,節約了人工刷版本、刷配置的時間,是滿足快速交付的重要手段。
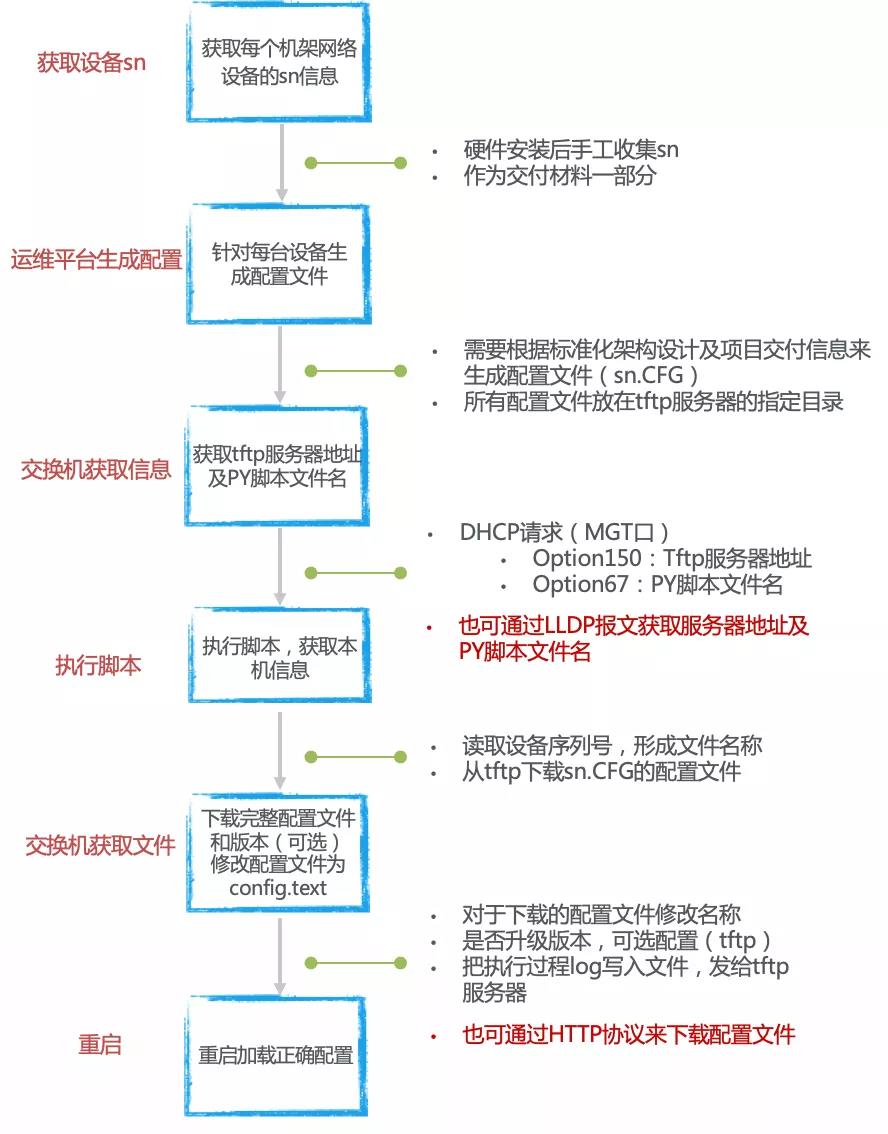
圖2 零配置自動部署管理技術流程
四、網絡配置與管理
Ansible
網絡承載的業務不會是一成不變的,為了滿足復雜多樣的需求可能會進行業務的調整變更。面對業務變更,往往需要運維工程師同時操作大量的網絡設備,此時如果依靠工程師逐臺登陸設備下發命令,大量的重復性工作一方面會導致運維效率低下,另一方面也很難避免產生一些人為配置失誤,因此需要一種便捷的運維管理工具幫助工程師解決批量配置管理網絡設備的問題。
社區中開源的運維管理工具有很多,都可以幫助運維人員批量完成特定任務,減少重復性工作,比如Puppet、SaltStack、Ansible等。在對比了這三個運維管理工具之后,我們發現Ansible更加輕量化,更容易被廣泛應用起來。
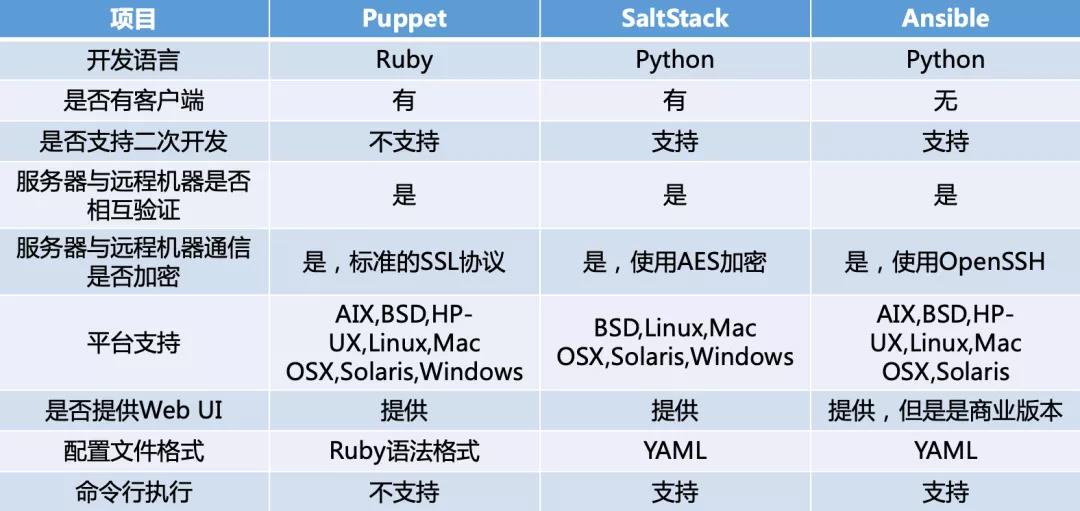
圖3 運維管理工具對比
從上述對比表中,我們不難發現Ansible的技術特點:
無客戶端
這是Ansible被廣泛應用的一個重要原因,被管設備上(如交換機)只需要支持SSH和Python2.5以上版本即可,不需要額外按照Ansible的客戶端進行適配;
模塊化
Ansible也可以視作沒有服務端,我們可以通過調用特定模塊,完成特定任務;
安全
基于OpenSSH的實現,加密遠程傳輸中的數據;
支持Playbooks編排任務
這個是Ansible的一大特色,Playbooks可以幫助運維人員將復雜任務碎片化,且能夠進行批量地部署復雜任務。Playbooks的編寫也基于易讀的YAML語法,操作容易。
五、網絡精細化監控
gNMI
(gRPC Network Management Interface)
提到網絡狀態監控,相信大家腦海中首先涌現的就是SNMP技術。的確,SNMP作為傳統的網絡監控手段已經被大家應用了很多年,但面對高性能計算、大數據、AI等業務就會有些力不從心。
首先從業務特征和需求來看,高帶寬業務會出現微突發的現象,因此需要我們能夠實時地監控設備的運行狀態。比如RDMA業務,需要對關鍵信息做監控,緩存隊列等實時狀態數據。
因此我們建議采用gRPC框架實現對網絡設備的精細化監控。
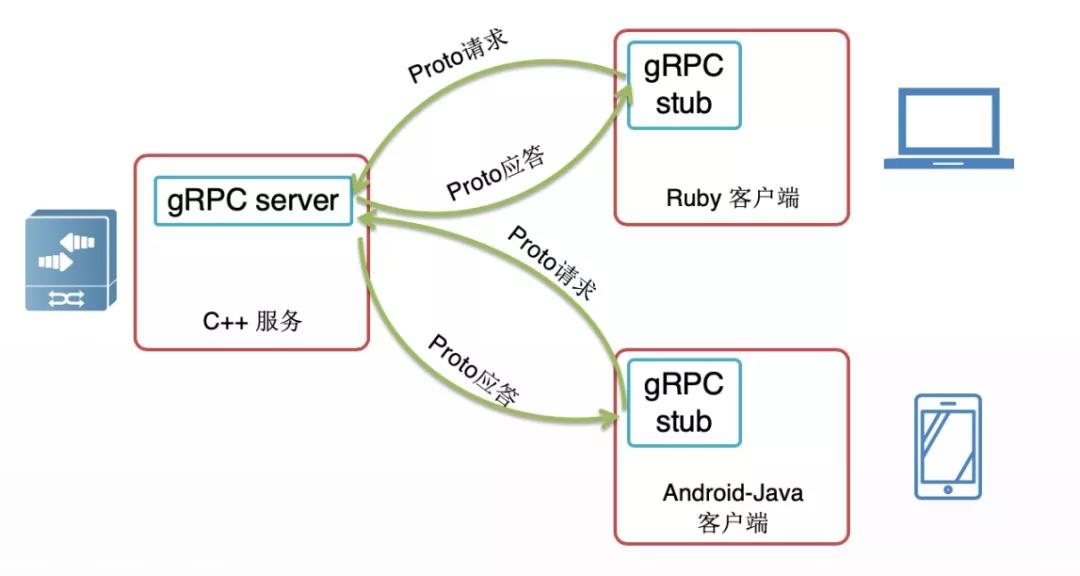
圖4 gRPC工作流程
gRPC是谷歌發布的基于HTTP2.0承載的高性能開源軟件框架,提供了支持多種編程語言的管理網絡配置和納管的方式。開源使大家更專注于業務層面內容,減少對底層協議框架的關注。gRPC采用了ProtoBuffer(PB)來做數據的序列化與反序列化封裝,用HTTP 2.0作為數據傳輸協議。
gRPC的傳輸效率非常高,也得益于這兩大核心技術。
Protocol Buffers:高效的數據格式,傳送二進制碼,消耗少,傳輸快
HTTP2.0:多路復用連接,二進制幀傳輸,首部壓縮
在網絡精細化監控這一環節中,越來越多的客戶開始應用gRPC來統一運維接口,拉齊設備的能力特性,提升效率,更加主動的感知網絡狀態,提早發現問題,防患于未然。關于gRPC技術的更詳細介紹,可以查閱前幾期的技術盛宴文章,由于篇幅的原因,作者在此不做深入展開。
六、問題定位
帶內流量分析(IFA,In-band Flow Analyzer)
網絡運維流程中棘手環節就是故障問題的定位。
以RDMA業務為例,該業務特征是對延時和丟包極其敏感,一旦發生了丟包就會大大降低業務性能,影響很大。因此我們除了能夠感知端到端的延時,還需要能檢測到異常抖動,知道在哪一跳出現了異常。
而在當前的架構下,網絡中存在了大量的路徑,每個業務流在每跳具體轉發到哪個物理端口上,依賴芯片Hash(哈希)的結果,這個對運維來說是不直觀的,我們希望給定一個業務流瞬間就知道每跳選擇了哪個物理接口。
基于上述業務訴求,IFA技術的應用給廣大運維同學帶來了福利。它可以用來精確確定特定流量的路徑及轉發時延等信息,并封裝成UDP報文發送給服務器進行分析。
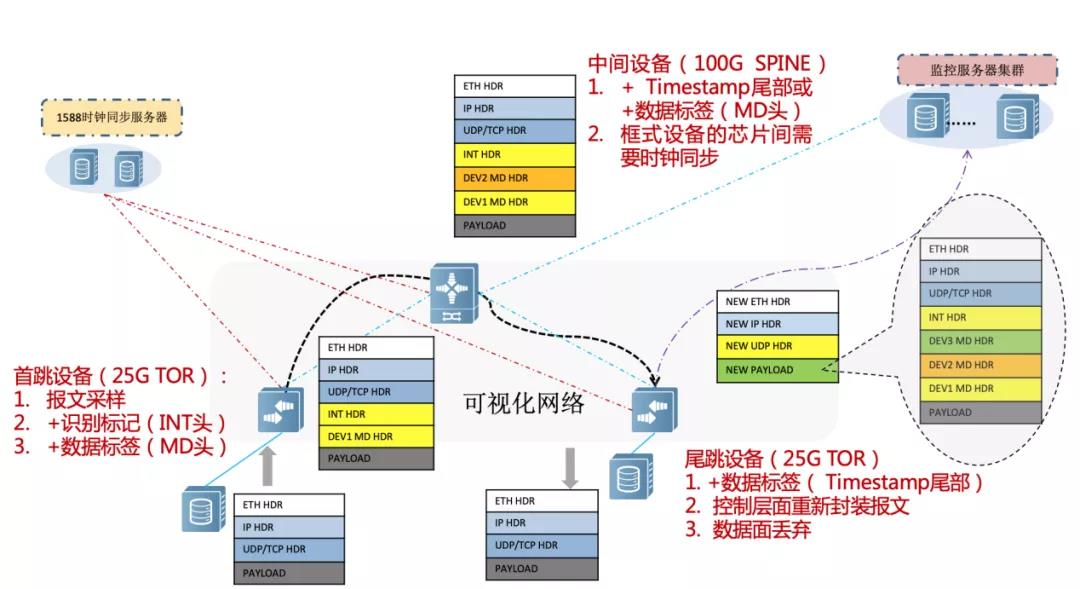
圖5 IFA技術原理
具體實現:
在入口首跳設備上進行指定會話的識別,通過采樣后,開始插入INT頭部;
后續轉發節點插入Metadata數據,包含設備id、入出端口、時間戳等;
尾跳設備重新構造UDP報文,并把采樣報文封裝到UDP報文的payload中,然后把UDP報文上送到監控服務器上。輸入文字
最終IFA的部署,可以常規的日常開啟,但是也可以針對發生故障時按需調用。
一些敏銳的讀者看到這里會提出一個疑問,RDMA業務既然對于路徑和丟包敏感,那么我們只上送那些路徑發生變化以及時間超過閾值的報文到服務器,再加以分析處理不就可以嗎?
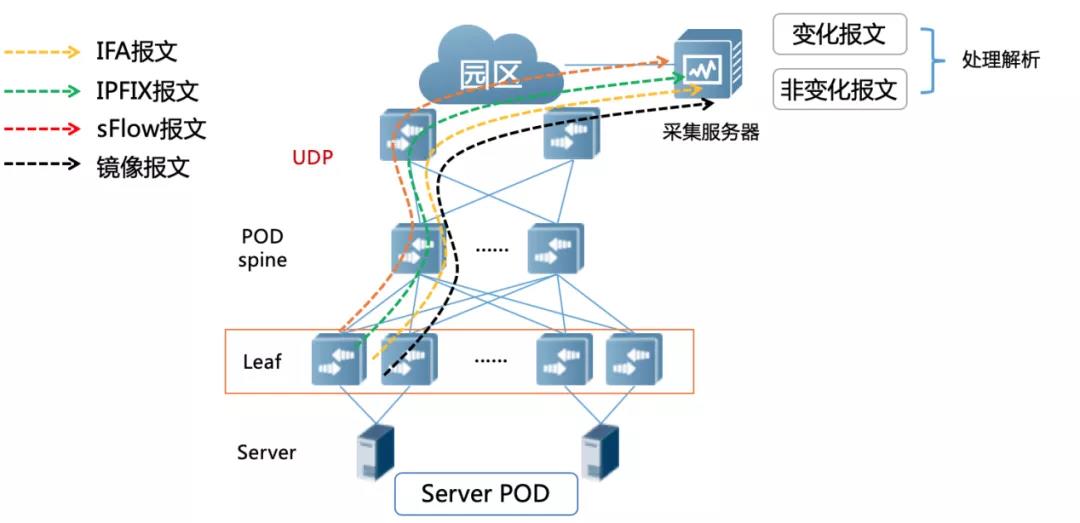
圖6網絡流量分析技術流程
沒錯,如果將報文都上送服務器確實會額外增加了服務器成本,不利于整網TCO優化,這種本末倒置的做法可能會直接導致IFA技術無法落地應用。
因此我們需要在流量到達服務器之前做一級過濾,將那些路徑和延時正常的報文都過濾掉,只上送異常報文到分析服務器,就可以大大降低了服務器的壓力。在這個過濾處理環節,我們建議采用基于可編程芯片的交換機來實現,因其強大的硬件處理能力可以獲得更好的價值收益。
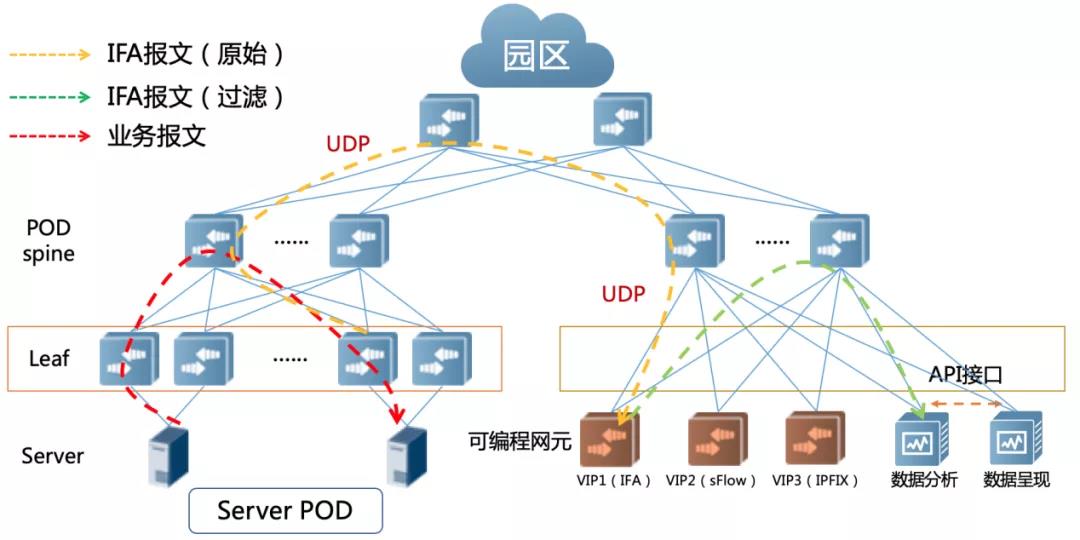
圖7 基于可編程網元的網絡可視化方案
六、故障處理
談到故障處理,我們需要先分析一下目前的運維模式。一般對于故障的處理流程都是先由業務方提交Case報障,運維團隊在系統上接到Case再去定位問題,分析原因,解決問題,屬于被動的救火式運維。迫于業務的緊急性,有的時候會讓運維工作陷入很大的壓力當中。
基于意圖網絡的智能分析平臺可以很好的幫助我們改變目前的運維模式,化被動為主動。
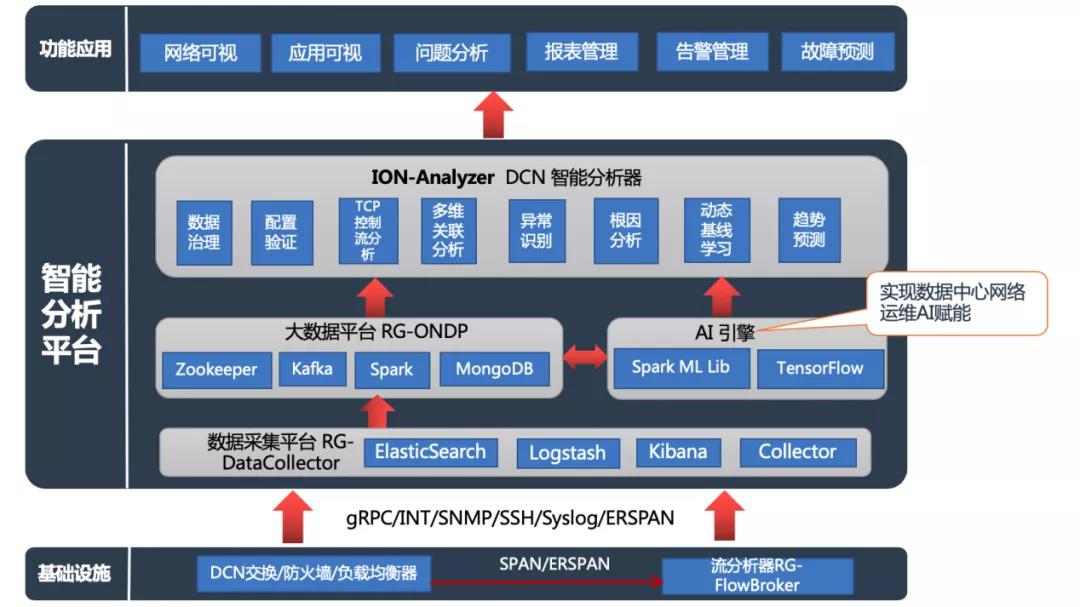
圖8 智能分析平臺架構
該平臺內置多個模塊,包括數據采集平臺、AI引擎、大數據分析平臺以及智能分析器。可以實現網絡及應用可視化,問題分析,故障預測等功能。
針對問題分析這一功能,可以幫助我們識別三大類故障,其中包括接入類、應用類以及網元類。基于問題的分析,該平臺也會提出調優及處理建議,幫助我們快速解決問題,恢復業務。
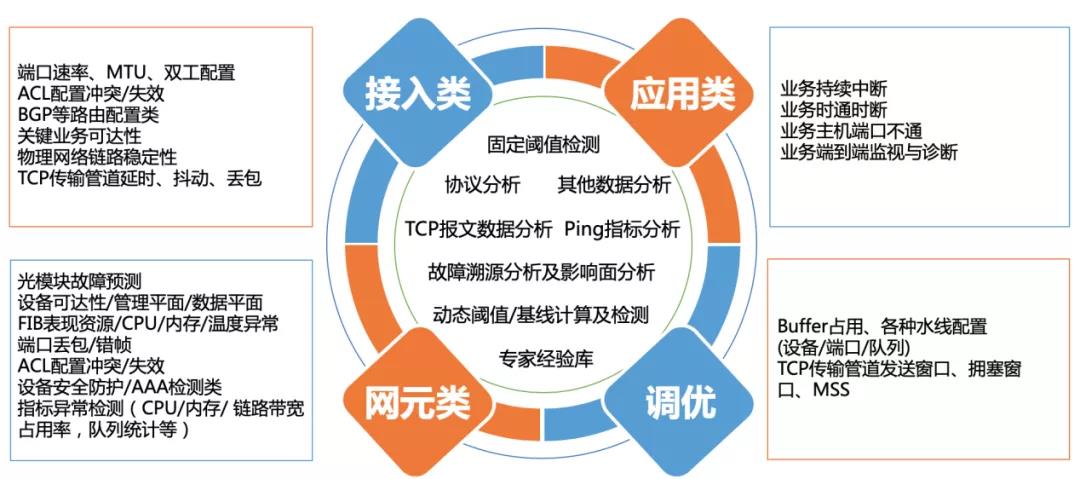
圖9 基于IBN的故障自動識別
關于IBN的詳細內容,未來會單獨做一期技術盛宴和大家一起分享,在這里先拋磚引玉一下,大家敬請期待后續的專題講解。
七、小結
看到這里,相信大家對新一代的數據中心運維技術也有所了解了。
銳捷網絡互聯網數據中心ENA(Easy Network Architecture,簡單網絡架構)解決方案正是基于單核心Box+多平面組網的基礎架構,面向運維全流程做升級迭代,從架構和運維兩個層面持續演進。
本文中提到的運維特性已經在銳捷網絡數據中心交換機產品中體現,這些是銳捷人長期深入業務場景、觀察研究、不斷打磨精品的具體呈現。我們深知,看清用戶痛點,以簡答的方式輔助用戶成功,這才是技術研發的第一要義。同時也希望每一位技術盛宴的讀者與我們分享您的真知灼見,我們共同發現、共同討論、共同成功!
相關推薦:





,RG-S6520-64CQ")




更多技術博文
-

 多速率交換機是什么?一文明白其原理、優勢與銳捷方案推薦
多速率交換機是什么?一文明白其原理、優勢與銳捷方案推薦本文用通俗語言詳解多速率交換機是什么,包括其工作原理、三大核心優勢及四大應用場景。文末為您推薦銳捷RG-S6100系列與RG-S5315-E系列交換機的選型方案,助您實現平滑網絡升級。
-
#交換機
-
-
 解密DeepSeek-V3推理網絡:MoE架構如何重構低時延、高吞吐需求?
解密DeepSeek-V3推理網絡:MoE架構如何重構低時延、高吞吐需求?DeepSeek-V3發布推動分布式推理網絡架構升級,MoE模型引入大規模專家并行通信,推理流量特征顯著變化,Decode階段對網絡時度敏感。網絡需保障低時延與高吞吐,通過端網協同負載均衡與擁塞控制技術優化性能。高效運維實現故障快速定位與業務高可用,單軌雙平面與Shuffle多平面組網方案在低成本下滿足高性能推理需求,為大規模MoE模型部署提供核心網絡支撐。
-
#交換機
-
-
 高密場景無線網絡新解法:銳捷Wi-Fi 7 AP 與 龍伯透鏡天線正式成團
高密場景無線網絡新解法:銳捷Wi-Fi 7 AP 與 龍伯透鏡天線正式成團銳捷網絡在中國國際大學生創新大賽(2025)總決賽推出旗艦Wi-Fi 7無線AP RG-AP9520-RDX及龍伯透鏡天線組合,針對高密場景實現零卡頓、低時延和高并發網絡體驗。該方案通過多檔賦形天線和智能無線技術,有效解決干擾與覆蓋問題,適用于場館、辦公等高密度環境,提供穩定可靠的無線網絡解決方案。
-
#無線網
-
#Wi-Fi 7
-
#無線
-
#放裝式AP
-
-
 打造“一云多用”的算力服務平臺:銳捷高職教一朵云2.0解決方案發布
打造“一云多用”的算力服務平臺:銳捷高職教一朵云2.0解決方案發布銳捷高職教一朵云2.0解決方案幫助學校構建統一云桌面算力平臺,支持教學、實訓、科研和AI等全場景應用,實現一云多用。通過資源池化和智能調度,提升資源利用效率,降低運維成本,覆蓋公共機房、專業實訓、教師辦公及AI教學等多場景需求,助力教育信息化從分散走向融合,推動規模化與個性化培養結合。
-
#云桌面
-
#高職教
-
















