






全調度以太網(GSE),中國智算網絡新標準
GSE網絡作為一種全調度以太網技術,專為大規模AI訓練集群設計,通過按需調度實現無損性能,提供靈活快速的部署方案,構建開放生態,顯著提升智算效率和運維體驗。






伴隨著智算技術的發展,越來越多的研究表明在 AI 訓練達到一定規模下能力才會涌現,在AI大模型的擴展定律和涌現能力的驅動下,AI大模型的參數規模越來越大。國內外業界已出現多個萬億參數模型,十萬億參數模型在不遠的將來也有望問世。公開資料表明,GPT-4 的參數體量比 GPT-3 增長了 10 倍,達到 1.8 萬億參數。國內的盤古、悟道大模型,其參數規模同樣超過了萬億。

注:數據截至23年3月,資料來源:北京智源人工智能研究院,中金公司研究院
美國當地時間7月22日,特斯拉CEO埃隆·馬斯克在旗下社交平臺X上表示,xAI團隊、X團隊、英偉達及其他支持公司已經于當地時間凌晨4時20分開始在“孟菲斯超級集群(Memphis Supercluster)”上進行訓練。“孟菲斯超級集群”由10萬個液冷H100 GPU組成,在單個RDMA結構上運行,是“世界上最強大的人工智能訓練集群”,該集群將被用于訓練xAI旗下第三代大語言模型Grok-3。大規模AI計算從萬卡進入到十萬卡時代。
大規模智算集群需要高性能的網絡連接,以保證各智算節點間的通信效率、數據吞吐和整個智算集群的算力性能。這對智算網絡提出了新的挑戰。
在基礎訓練模型中,一方面多任務混合部署,傳統以太網源端發流直接采用網絡“Push”流量模式,不考慮網絡及接收端的接受能力,導致網絡擁塞,使得 GPU 處于等待狀態,造成梯度和參數同步過程中算力資源浪費較大,傳統的 RoCE 網絡有效吞吐僅為 50%;另一方面,智算集群網絡流量呈現出數據流數目少、單流流量大的特點,在傳統網絡均衡算法下容易引發HASH 沖突,造成鏈路丟包,導致訓練異常中斷,極大影響訓練效率。時代呼喚 “零丟包”、“高吞吐”、“低時延” 為核心特征的無損智算網絡設備,來解決超大規模 AI 計算通信效率低的問題。

當前全球已商用的智算網絡技術,主要有2大流派:
流派1:IB(InfiniBand)網絡,是目前市場占有率最高的智算網絡解決方案,IB 技術較為封閉,市場基本被英偉達壟斷,不符合全球開放生態的產業共識。
流派2:RoCE(RDMA over Converged Ethernet)網絡,RoCE廣泛應用于需要高帶寬和低延遲的網絡,在傳統的通算領域有很高的占有率,但是RoCE在智算網絡中存在流量HASH極化的問題,需要輔助以各種均衡調參進行智算網絡的適配。
為了更好的提升智算網絡性能,更好的服務于大規模 AI 計算,出現了更多的新型技術流派:
新技術流派1:UEC(Ultra Ethernet Consortium)網絡,2023 年 7 月Linux 基金會與全球頭部科技企業聯合成立 UEC 以太網創新聯盟,其創始成員包括AMD、Arista、博通、思科、HPE、Intel、Meta、微軟、Oracle和Eviden,致力于從物理層、鏈路層、傳輸層、軟件層改進以太網技術的革新,來滿足 AI 計算網絡的需求。
新技術流派2:GSE(Global Scheduling Ethernet)網絡,中國智算中心的建設熱潮始于 2020 年,目前已有 40 多個城市在建設或在建智算中心。智算中心建設步伐加快,但國內的網絡技術發展卻滯后于 AI 大模型的演進。AI 網絡技術上的競爭已經成為中美技術博弈的新戰場。在這樣嚴峻的形勢下,2023 年 5 月,中國移動聯合產業界發布了全調度以太網(GSE)白皮書,同年8 月全調度以太網推進計劃正式開啟,標志著具有中國自主技術的 GSE 流派正式誕生。

GSE 是一個開放的生態組織,2023 年 9 月,中國移動發布GSE 交換機原型系統樣機。2024 年 1 月在移動實驗室完成了GSE 交換機多廠商設備的互聯互通測試。

GSE 網絡,專為大規模 AI 訓練集群打造
按需調度,性能無損
GSE 網絡基于 PKTC 容器技術,實現了高精度的網絡負載均衡,從根本上改善了傳統 AI 算力網絡鏈路的帶寬利用率;采用基于 DQSQ 的信令申請調度技術,數據流以“Pull”的方式進行轉發,突破了傳統以太網的性能瓶頸,網絡性能提升至 95%以上。
在多業務部署場景下,相較于傳統 RoCE 網絡性能大幅下降,GSE 交換機能保持與單業務場景持平的網絡轉發性能,大幅提升網絡效率。
場景靈活,快速部署
GSE純網側方案即可滿足智算無損需求,可搭配國產 GPU 集成網卡,降低端側網卡要求。GSE技術原生解決了適配不同大模型訓練的網絡調參問題,避免了傳統RoCE達數天甚至數周的網絡參數調優,在算力昂貴、AI大模型競爭激烈的市場中,為客戶帶來靈活的算力網絡建設方案,縮短了訓練調優周期,幫助客戶快速搶占市場先機。

全局解耦,開放生態
GSE 技術體系支持標準以太網標準,新增標準協議頭,完成基于以太報文的轉發,實現端到端的多廠家設備互聯互通,構建了多廠家充分參與的開放生態,全面激活國內 AI 產業鏈,促進智算產業創新發展。
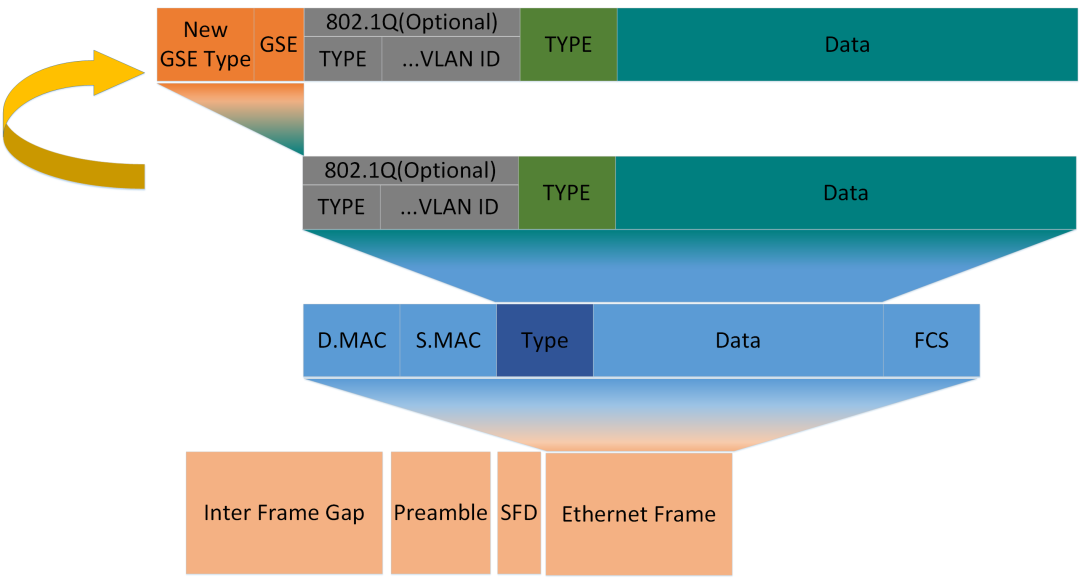
GSE標準協議頭
總結
銳捷網絡致力于與 GSE 生態一起打造中國的AIGC智算網絡新標準。GSE 網絡設備基于標準以太網在轉發架構方面進行技術創新,突破傳統以太網的性能瓶頸,拓展智算網絡的應用場景,充分滿足國產化智算集群網絡的需求,為客戶帶來了三大核心價值:提高智算效率,增強運維體驗,開放生態解耦。
相關標簽:


點贊


更多技術博文
-

 解密DeepSeek-V3推理網絡:MoE架構如何重構低時延、高吞吐需求?
解密DeepSeek-V3推理網絡:MoE架構如何重構低時延、高吞吐需求?DeepSeek-V3發布推動分布式推理網絡架構升級,MoE模型引入大規模專家并行通信,推理流量特征顯著變化,Decode階段對網絡時度敏感。網絡需保障低時延與高吞吐,通過端網協同負載均衡與擁塞控制技術優化性能。高效運維實現故障快速定位與業務高可用,單軌雙平面與Shuffle多平面組網方案在低成本下滿足高性能推理需求,為大規模MoE模型部署提供核心網絡支撐。
-
#交換機
-
-
 高密場景無線網絡新解法:銳捷Wi-Fi 7 AP 與 龍伯透鏡天線正式成團
高密場景無線網絡新解法:銳捷Wi-Fi 7 AP 與 龍伯透鏡天線正式成團銳捷網絡在中國國際大學生創新大賽(2025)總決賽推出旗艦Wi-Fi 7無線AP RG-AP9520-RDX及龍伯透鏡天線組合,針對高密場景實現零卡頓、低時延和高并發網絡體驗。該方案通過多檔賦形天線和智能無線技術,有效解決干擾與覆蓋問題,適用于場館、辦公等高密度環境,提供穩定可靠的無線網絡解決方案。
-
#無線網
-
#Wi-Fi 7
-
#無線
-
#放裝式AP
-
-
 打造“一云多用”的算力服務平臺:銳捷高職教一朵云2.0解決方案發布
打造“一云多用”的算力服務平臺:銳捷高職教一朵云2.0解決方案發布銳捷高職教一朵云2.0解決方案幫助學校構建統一云桌面算力平臺,支持教學、實訓、科研和AI等全場景應用,實現一云多用。通過資源池化和智能調度,提升資源利用效率,降低運維成本,覆蓋公共機房、專業實訓、教師辦公及AI教學等多場景需求,助力教育信息化從分散走向融合,推動規模化與個性化培養結合。
-
#云桌面
-
#高職教
-
-
 醫院無線升級必看:“全院零漫游”六大謎題全解析
醫院無線升級必看:“全院零漫游”六大謎題全解析銳捷網絡的全院零漫游方案是新一代醫療無線解決方案,專為智慧醫院設計,通過零漫游主機和天線入室技術實現全院覆蓋和移動零漫游體驗。方案支持業務擴展全適配,優化運維管理,確保內外網物理隔離安全,并便捷部署物聯網應用,幫助醫院提升網絡性能,支持舊設備利舊升級,降低成本。
-
#醫療
-
#醫院網絡
-
#無線
-















